溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關使用NodeJS怎么讀取分析Nginx錯誤日志,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
錯誤日志分析
首先我們要讀取Nginx日志,我們可以看到Nginx的錯誤日志格式一般都是這樣子,需要注意的是Nginx的錯誤日志格式是差不多的因為無法設置日志格式只能設置日志錯誤等級所以我們分析的時候很方便

這里我們用到readline
逐行讀取,簡單來說可以做
文件逐行讀取:比如說進行日志分析。
自動完成:比如輸入npm,自動提示"help init install"。
命令行工具:比如npm init這種問答式的腳手架工具。 這里我們主要做日志分析其他的感興趣可以琢磨一下
實現方法
const readline = require('readline');
const fs = require('fs');
const path = require('path');
console.time('readline-time')
const rl = readline.createInterface({
input: fs.createReadStream(path.join(__dirname, '../public/api.err.log'), {
start: 0,
end: Infinity
}),
});
let count = 0;
rl.on('line', (line) => {
const arr = line.split(', ');
const time = arr[0].split('*')[0].split('[')[0].replace(/\//g, '-');//獲取到時間
const error = arr[0].split('*')[1].split(/\d\s/)[1];//錯誤原因
const client = arr[1].split(' ')[1];//請求的客戶端
const server = arr[2].split(' ')[1];//請求的網址
const url = arr[3].match(/\s\/(\S*)\s/)[0].trim()//獲取請求鏈接
const upstream = arr[4].match(/(?<=").*?(?=")/g)[0];//獲取上游
const host = arr[5].match(/(?<=").*?(?=")/g)[0];//獲取host
const referrer = arr[6] ? arr[6].match(/(?<=").*?(?=")/g)[0] : '';//來源
console.log(`時間:${time}-原因:${error}-客戶端:${client}-網址:${server}-地址:${url}-上游:${upstream}-主機:${host}-來源:${referrer}`);
count++;
});
rl.on('close', () => {
let size = fs.statSync(path.join(__dirname, '../public/api.err.log')).size;
console.log(`讀取完畢:${count};文件位置:${size % 2 === 0}`);
console.timeEnd('readline-time')
});上面代碼有幾點需要注意的是會創建一個文件可讀流然后由于演示所以我是直接找的本地地址如果是生產環境的話大家可以直接填寫服務器上的錯誤日志地址,如果沒有Nginx錯誤日志分割的話每天會產生很多日志,createReadStream讀取幾十M的文件還好如果讀取幾百M或者上G的容量日志這會造成性能問題,所以我們需要在每次createReadStream沒必要每次從0字節開始讀取,ceateReadStream提供了start和end

所以我們每次可以在讀取完之后記錄一下當前文件字節大小下一次讀取文件就是可以用該文件上次的大小開始讀取
let size = fs.statSync(path.join(__dirname, '../public/api.err.log')).size;
我們可以對比一下每次從0字節開始讀取和從指定字節讀取
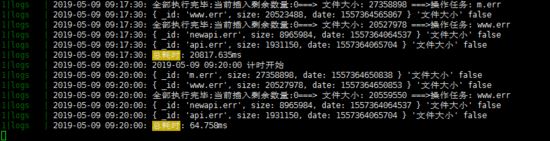
保存數據進行分析
這里我是用node-schedule這個庫進行定時保存錯誤日志和linux的cron差不多,用的mongodb保存數據,這里更推薦大家用elasticsearch來做日志分析
rl.on('close', async () => {
let count = 0;
for (let i of rlist) {
count++;
if (count % 500 === 0) {
const res = await global.db.collection('logs').bulkWrite(rlist.slice(count, count + 500), { ordered: false, w: 1 }).catch(err => { console.error(`批量插入出錯${err}`) });
} else if (count === rlist.length - 1) {
//批量插入 數據
const res = await global.db.collection('logs').bulkWrite(rlist.slice(rlist - (rlist % 500), rlist.length), { ordered: false, w: 1 });
let size = fs.statSync(addres).size;
size = size % 2 === 0 ? size : size + 1;//保證字節大小是偶數 不然會出現讀取上行內容不完整的情況
count = 0;
rlist.length = [];
//更新數據庫里面文件的size
global.db.collection('tasks').updateOne({ _id: addre }, { $set: { _id: addre, size, date: +new Date() } }, { upsert: true });
}
}
resolve(true);
})上面主要是500條保存一次,因為我用的是批量插入然后mongodb有限制一次性最多插入16M數據的限制,所以大家看自己清空決定一次性插入多少條 猶豫對readline的實現比較感興趣,就去翻閱了一下源碼發現并不是我們想的那么復雜, readline源碼 ,下面貼一下line事件的源碼,想繼續深入的同學可以看看全部的源碼
if (typeof s === 'string' && s) {
var lines = s.split(/\r\n|\n|\r/);
for (var i = 0, len = lines.length; i < len; i++) {
if (i > 0) {
this._line();
}
this._insertString(lines[i]);
}
}
...
Interface.prototype._line = function() {
const line = this._addHistory();
this.clearLine();
this._onLine(line);
};
...
Interface.prototype._onLine = function(line) {
if (this._questionCallback) {
var cb = this._questionCallback;
this._questionCallback = null;
this.setPrompt(this._oldPrompt);
cb(line);
} else {
this.emit('line', line);
}
};保存的數據需要進行分析比如哪個IP訪問最多哪條錯誤最多可以用聚合來進行分析貼出示例分析某個IP在某一天訪問出錯最多的原因
db.logs.aggregate(
// Pipeline
[
// Stage 1
{
$group: {
'_id': { 'client': '114.112.163.28', 'server': '$server', 'error': '$error', 'url': '$url', 'upstream': '$upstream','date':'$date' ,'msg':'$msg' } ,
'date':{'$addToSet':'$date'},
count: { '$sum': 1 }
}
},
// Stage 2
{
$match: {
count: { $gte: 1 },
date: ['2019-05-10']
}
},
{
$sort: {
count: -1
}
},
],
// Options
{
cursor: {
batchSize: 50
},
allowDiskUse: true
}
);以上就是使用NodeJS怎么讀取分析Nginx錯誤日志,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





