溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關python中selenium如何查找隱藏元素和實現自動播放視頻功能的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
在使用python做爬蟲的過程中,有些頁面的的部分數據是通過js異步加載的,js調用接口的請求中有時還帶有些加密的參數很難破解無法使用requests這樣的包直接爬取數據,因此需要借助seleniu來完成js的自動加載。
通過selenium 模擬瀏覽器的真是操作來獲取頁面中的所有請求,并且可以查找到一下頁面上一些隱藏的元素,這些元素在html源碼中無法看到,并且和能通過xpath和正則來捕獲,因此需要使用selenium來查找隱藏元素,例如視頻網站的播放按鈕
代碼如下
import time
# 導入自動化測試模塊
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.common.action_chains import ActionChains
import re
import json
d = DesiredCapabilities.CHROME
d['loggingPrefs'] = {'performance': 'ALL'}
# 設置谷歌瀏覽器參數,設置語言和瀏覽器版本(使用真實瀏覽器頭信息代替字符瀏覽器頭)
options = webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36"')
# 建立一個瀏覽器對象,調用PhantoJS來生成一個對象
browser = webdriver.Chrome(executable_path='D:\Python36\chromedriver.exe', chrome_options=options, desired_capabilities=d)
video_url = 'https://v.youku.com/v_show/id_XNDIyMjU1NjgzMg==.html?spm=a2ha1.12675304.m_2556_c_8261.d_2&s=a4de6bdc5675415ea280&scm=20140719.manual.2556.show_a4de6bdc5675415ea280'
browser.get(video_url)
time.sleep(10)
menu = browser.find_element_by_css_selector(".ykplayer") # 查找頁面隱藏元素
# menu = browser.find_element_by_css_selector("div.x-video-play-ico.i-pause > dt").text
print(menu)
print(type(menu))
menu = browser.find_element_by_css_selector(".ykplayer").text # 獲得隱藏元素的內容
print(menu)
print(type(menu))
###################
#ActionChains(browser).click()
browser.find_element_by_css_selector('.ykplayer').click() # 查找到隱藏元素位置后執行點擊鼠標左鍵操作
time.sleep(10)
lo = browser.get_log('performance') # 捕獲瀏覽器network中的數據
browser.get_network_conditions()
datalist = []
for entry in lo:
try:
print(entry)
datalist.append(entry)
except Exception as e:
continue
browser.close()視頻中被播放按鈕是一個隱藏元素,用xpaht定位到指定的標簽后也無法獲取這個標簽中的元素
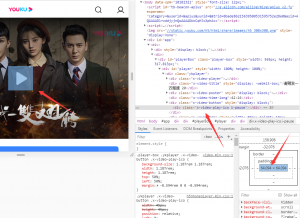
通過 browser.find_element_by_css_selector(“.ykplayer”) 方法查找 .ykplayer 可以查找到,查找后輸出的內容這個視頻的標題,這樣就實現了使用chromedriver 自動播放視頻的功能
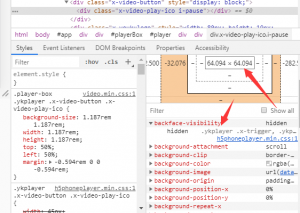
這里雖然實現的視頻自動播放,但是請求優酷視頻的視頻地址的接口調用的結果卻依然沒法通過 browser.get_log(‘performance')來獲得,原因是有一部分數據沒有全部加載,但接口實際已經取得了完整的數據。雖然可以通過 get_log中的結果獲得請求的地址,但是這個請求的地址在此使用requests進行請求會提示無權訪問,可以看到這個請求已經有請求體了,但是使用get_log卻無法捕獲。
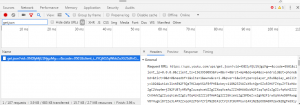
而且這個請求地址是一次性的,在次請求的結果是沒權限
{"cost":0.003000000026077032,"data":{"error":{"note":"客戶端無權播放,201","code":-6004}},"e":{"code":0,"provider":"hsfprovider","desc":""}}要解決這個問題需要使用到browsermob-proxy
利用BrowserMob Proxy實現類似chrome的開發者工具中network的功能,
監控瀏覽器中該頁面的request,獲取對應的response,從而得到對應的json數據。
其大致原理是設置一個本地代理,并監控瀏覽器通過該代理的網絡活動。
最后,我的解決方案是:python3 + selenium + chrome + browsermob-proxy
下載好BrowserMob Proxy和chromedriver,并記住對應的路徑,稍后需要配置。
https://bmp.lightbody.net/
http://npm.taobao.org/mirrors/chromedriver/
另外,使用browsermob-proxy需要安裝Java依賴環境,首次安裝后可能需要重啟。
python的環境可安裝anaconda獲得,然后是安裝額外的python庫
pip install browsermob-proxy pip install selenium
軟件環境配置完成后,可開始搭建抓取動態網頁的框架,
下面是我做的一個簡單框架(browsermonitor.py),其中未涉及數據的加工,可針對需要抓取的網頁,直接繼承后,根據需求加工數據:
?
"""step 1 導入依賴庫"""
from os import path
from browsermobproxy import Server
from selenium import webdriver
import re
"""step 2 新建瀏覽器監控類"""
class Monitor(object):
"""
step 3 配置chromedriver 和 browermobproxy 路徑
需要使用完整路徑,否則browsermobproxy無法啟動服務
我是將這兩個部分放到了和monitor.py同一目錄
同時設置chrome為屏蔽圖片,若需要抓取圖片可自行修改
"""
PROXY_PATH = path.abspath("./browsermob-proxy/bin/browsermob-proxy.bat")
CHROME_PATH = path.abspath("./chromedriver.exe")
CHROME_OPTIONS = {"profile.managed_default_content_settings.images":2}
def __init__(self):
"""
類初始化函數暫不做操作
"""
pass
def initProxy(self):
"""
step 4 初始化 browermobproxy
設置需要屏蔽的網絡連接,此處屏蔽了css,和圖片(有時chrome的設置會失效),可加快網頁加載速度
新建proxy代理地址
"""
self.server = Server(self.PROXY_PATH)
self.server.start()
self.proxy = self.server.create_proxy()
self.proxy.blacklist(["http://.*/.*.css.*","http://.*/.*.jpg.*","http://.*/.*.png.*","http://.*/.*.gif.*"],200)
def initChrome(self):
"""
step 5 初始化selenium, chrome設置
將chrome的代理設置為browermobproxy新建的代理地址
"""
chromeSettings = webdriver.ChromeOptions()
chromeSettings.add_argument('--proxy-server={host}:{port}'.format(host = "localhost", port = self.proxy.port))
chromeSettings.add_experimental_option("prefs", self.CHROME_OPTIONS)
self.driver = webdriver.Chrome(executable_path = self.CHROME_PATH, chrome_options = chromeSettings)
def genNewRecord(self, name = "monitor", options={'captureContent':True}):
"""
step 6 新建監控記錄,設置內容監控為True
"""
self.proxy.new_har(name,options = options)
def getContentText(self, targetUrl):
"""
step 7 簡單的獲取目標數據的函數
其中 targetUrl 為瀏覽器獲取對應數據調用的url,需要用正則表達式表示
"""
if self.proxy.har['log']['entries']:
for loop_record in self.proxy.har['log']['entries']:
try:
if re.fullmatch(targetUrl , loop_record["request"]['url']):
return loop_record["response"]['content']["text"]
except Exception as err:
print(err)
continue
return None
def Start(self):
"""step 8 配置monitor的啟動順序"""
try:
self.initProxy()
self.initChrome()
except Exception as err:
print(err)
def Quit(self):
"""
step 9 配置monitor的退出順序
代理sever的退出可能失敗,目前是手動關閉,若誰能提供解決方法,將不勝感激
"""
self.driver.close()
self.driver.quit()
try:
self.proxy.close()
self.server.process.terminate()
self.server.process.wait()
self.server.process.kill()
except OSError:
pass
if __name__ == '__main__':
monitor = Monitor()
monitor.Start()
monitor.genNewRecord()
# 這使用優酷視頻的地址
url = 'https://v.youku.com/v_show/id_XNDIyMjU1NjgzMg==.html?spm=a2ha1.12675304.m_2556_c_8261.d_2&s=a4de6bdc5675415ea280&scm=20140719.manual.2556.show_a4de6bdc5675415ea280'
monitor.driver.get(url)
targetUrl = "https://ups.youku.com/ups/get.json.*" # 這是獲取視頻播放地址的接口請求的前綴
text = monitor.getContentText(targetUrl)
monitor.Quit()感謝各位的閱讀!關于“python中selenium如何查找隱藏元素和實現自動播放視頻功能”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





