溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何在Python中使用Yellowbrick實現可視化?很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
Yellowbrick主要包含的組件如下:
Visualizers Visualizers也是estimators(從數據中習得的對象),其主要任務是產生可對模型選擇過程有更深入了解的視圖。從Scikit-Learn來看,當可視化數據空間或者封裝一個模型estimator時,其和轉換器(transformers)相似,就像"ModelCV" (比如 RidgeCV, LassoCV )的工作原理一樣。Yellowbrick的主要目標是創建一個和Scikit-Learn類似的有意義的API。其中最受歡迎的visualizers包括: 特征可視化 Rank Features: 對單個或者兩兩對應的特征進行排序以檢測其相關性 Parallel Coordinates: 對實例進行水平視圖 Radial Visualization: 在一個圓形視圖中將實例分隔開 PCA Projection: 通過主成分將實例投射 Feature Importances: 基于它們在模型中的表現對特征進行排序 Scatter and Joint Plots: 用選擇的特征對其進行可視化 分類可視化 Class Balance: 看類的分布怎樣影響模型 Classification Report: 用視圖的方式呈現精確率,召回率和F1值 ROC/AUC Curves: 特征曲線和ROC曲線子下的面積 Confusion Matrices: 對分類決定進行視圖描述 回歸可視化 Prediction Error Plot: 沿著目標區域對模型進行細分 Residuals Plot: 顯示訓練數據和測試數據中殘差的差異 Alpha Selection: 顯示不同alpha值選擇對正則化的影響 聚類可視化 K-Elbow Plot: 用肘部法則或者其他指標選擇k值 Silhouette Plot: 通過對輪廓系數值進行視圖來選擇k值 文本可視化 Term Frequency: 對詞項在語料庫中的分布頻率進行可視化 t-SNE Corpus Visualization: 用隨機鄰域嵌入來投射文檔
這里以癌癥數據集為例繪制ROC曲線,如下:
def testFunc1(savepath='Results/breast_cancer_ROCAUC.png'): ''' 基于癌癥數據集的測試 ''' data=load_breast_cancer() X,y=data['data'],data['target'] X_train, X_test, y_train, y_test = train_test_split(X, y) viz=ROCAUC(LogisticRegression()) viz.fit(X_train, y_train) viz.score(X_test, y_test) viz.poof(outpath=savepath)
結果如下:

結果看起來也是挺美觀的。
之后用平行坐標的方法對高維數據進行作圖,數據集同上:
def testFunc2(savepath='Results/breast_cancer_ParallelCoordinates.png'): ''' 用平行坐標的方法對高維數據進行作圖 ''' data=load_breast_cancer() X,y=data['data'],data['target'] print 'X_shape: ',X.shape #X_shape: (569L, 30L) visualizer=ParallelCoordinates() visualizer.fit_transform(X,y) visualizer.poof(outpath=savepath)
結果如下:
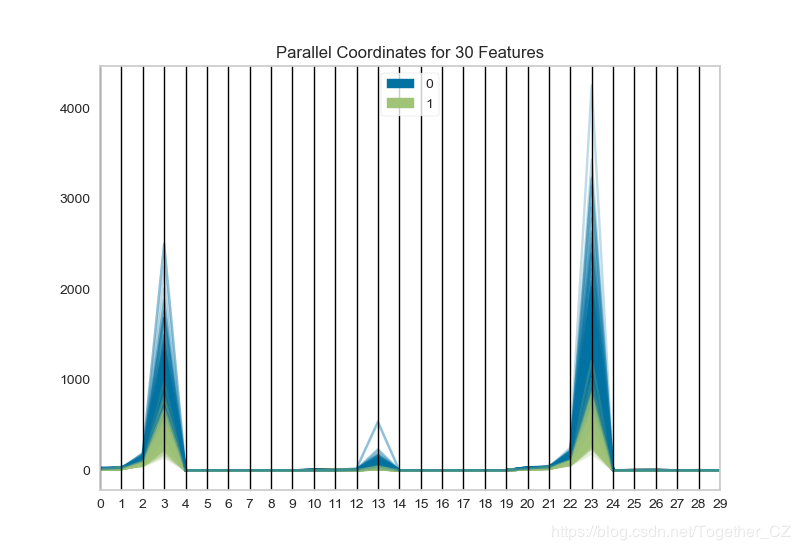
這個最初沒有看明白什么意思,其實就是高維特征數據的可視化分析,這個功能還可以對原始數據進行采樣,之后再繪圖。
基于癌癥數據集,使用邏輯回歸模型來分類,繪制分類報告
def testFunc3(savepath='Results/breast_cancer_LR_report.png'): ''' 基于癌癥數據集,使用邏輯回歸模型來分類,繪制分類報告 ''' data=load_breast_cancer() X,y=data['data'],data['target'] model=LogisticRegression() visualizer=ClassificationReport(model) X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=42) visualizer.fit(X_train,y_train) visualizer.score(X_test,y_test) visualizer.poof(outpath=savepath)
結果如下:
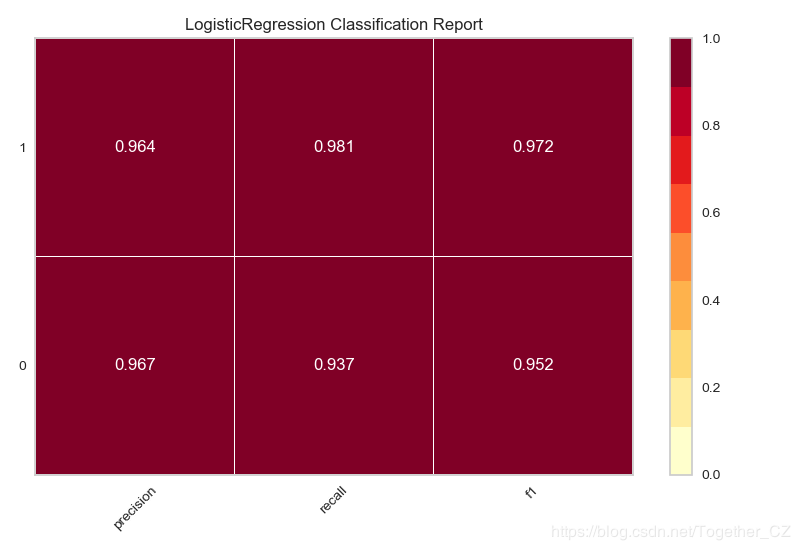
這樣的結果展現方式還是比較美觀的,在使用的時候發現了這個模塊的一個不足的地方,就是:如果連續繪制兩幅圖片的話,第一幅圖片就會累加到第二幅圖片中去,多幅圖片繪制亦是如此,在matplotlib中可以使用plt.clf()方法來清除上一幅圖片,這里沒有找到對應的API,希望有找到的朋友告知一下。
接下來基于共享單車數據集進行租借預測,具體如下:
首先基于特征對相似度分析方法來分析共享單車數據集中兩兩特征之間的相似度
def testFunc5(savepath='Results/bikeshare_Rank2D.png'):
'''
共享單車數據集預測
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"
]]
y=data["riders"]
visualizer=Rank2D(algorithm="pearson")
visualizer.fit_transform(X)
visualizer.poof(outpath=savepath)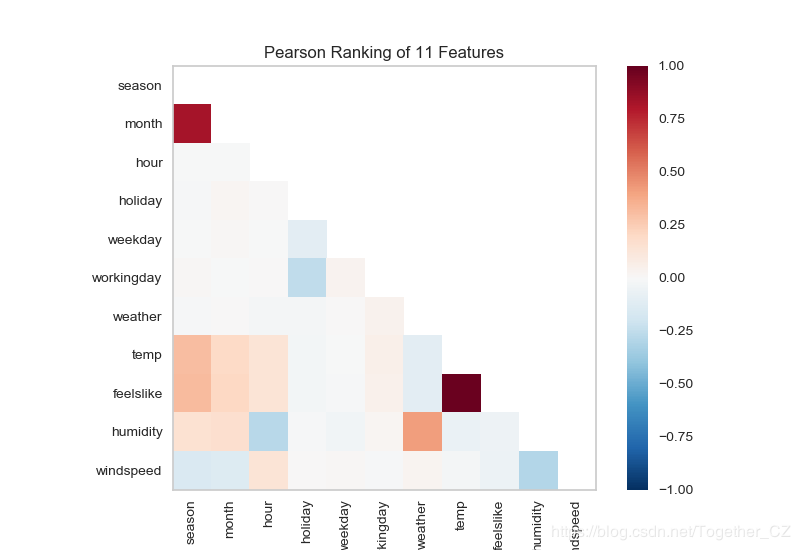
基于線性回歸模型實現預測分析
def testFunc7(savepath='Results/bikeshare_LinearRegression_ResidualsPlot.png'):
'''
基于共享單車數據使用線性回歸模型預測
'''
data = pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
visualizer=ResidualsPlot(LinearRegression())
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof(outpath=savepath)結果如下:

基于共享單車數據使用AlphaSelection
def testFunc8(savepath='Results/bikeshare_RidgeCV_AlphaSelection.png'):
'''
基于共享單車數據使用AlphaSelection
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
alphas=np.logspace(-10, 1, 200)
visualizer=AlphaSelection(RidgeCV(alphas=alphas))
visualizer.fit(X, y)
visualizer.poof(outpath=savepath)結果如下:
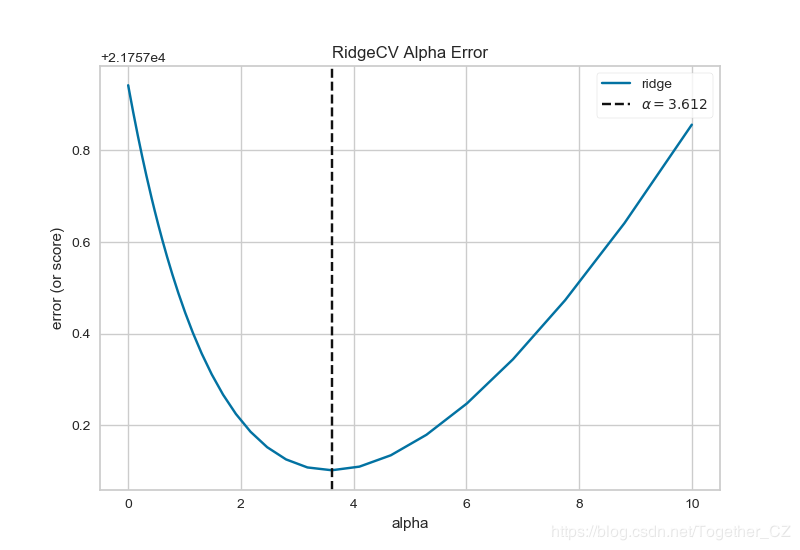
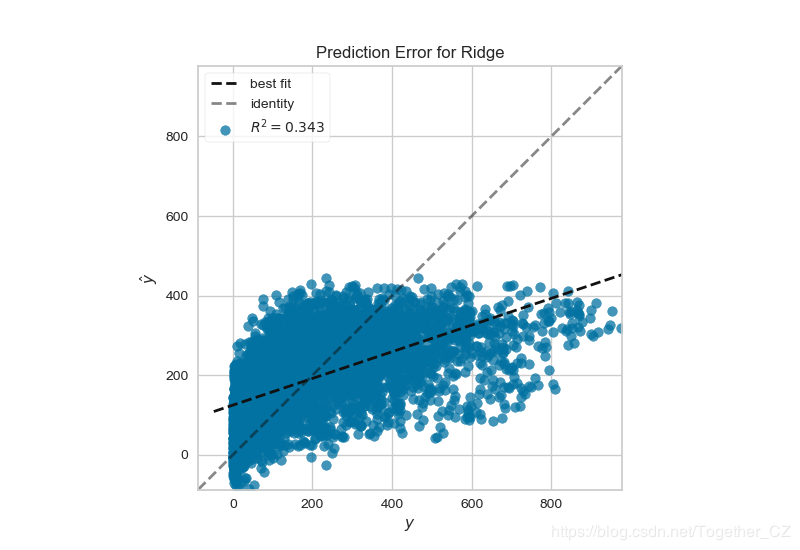
基于共享單車數據繪制預測錯誤圖
def testFunc9(savepath='Results/bikeshare_Ridge_PredictionError.png'):
'''
基于共享單車數據繪制預測錯誤圖
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
visualizer=PredictionError(Ridge(alpha=3.181))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof(outpath=savepath)
blog.csdn.net/Together_CZ/article/details/86640784結果如下:
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





