溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文實例講述了Python通過VGG16模型實現圖像風格轉換操作。分享給大家供大家參考,具體如下:
卷積網絡每一層的激活值可以看作一個分類器,多個分類器組成了圖像在這一層的抽象表示,而且層數越深,越抽象
內容特征:圖片中存在的具體元素,圖像輸入到CNN后在某一層的激活值
風格特征:繪制圖片元素的風格,各個內容之間的共性,圖像在CNN網絡某一層激活值之間的關聯
風格轉換:在一幅圖片內容特征的基礎上添加另一幅圖片的風格特征從而生成一幅新的圖片。在卷積模型訓練中,通過輸入固定的圖片來調整網絡的參數從而達到利用圖片訓練網絡的目的。而在生成特定風格圖片時,固定已有的網絡參數不變,調整圖片從而使圖片向目標風格轉化。在內容風格轉換時,調整圖像的像素值,使其向目標圖片在卷積網絡輸出的內容特征靠攏。在風格特征計算時,通過多個神經元的輸出兩兩之間作內積求和得到Gram矩陣,然后對G矩陣做差求均值得到風格的損失函數。
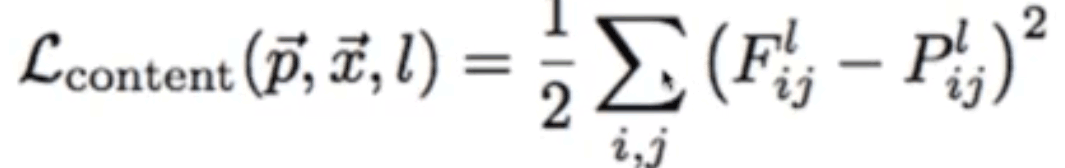
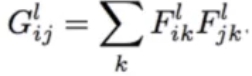
將內容損失函數和風格損失函數對應乘以權重再加起來就得到了總的損失函數,最后的生成圖既有內容特征也有風格特征
通過預訓練好的Vgg16模型來對圖片進行風格轉換,首先需要準備好vgg16的模型參數。鏈接: https://pan.baidu.com/s/1shw2M3Iv7UfGjn78dqFAkA 提取碼: ejn8
通過numpy.load()導入并查看參數的內容:
import numpy as np
data=np.load('./vgg16_model.npy',allow_pickle=True,encoding='bytes')
# print(data.type())
data_dic=data.item()
# 查看網絡層參數的鍵值
print(data_dic.keys())
打印鍵值如下,可以看到分別有不同的卷積和全連接層:
dict_keys([b'conv5_1', b'fc6', b'conv5_3', b'conv5_2', b'fc8', b'fc7', b'conv4_1', b'conv4_2', b'conv4_3', b'conv3_3', b'conv3_2', b'conv3_1', b'conv1_1', b'conv1_2', b'conv2_2', b'conv2_1'])
接著查看具體每層的參數,通過data_dic[key]可以獲取到key對應層次的參數,例如可以看到卷積層1_1的權值w為3個3×3的卷積核,對應64個輸出通道
# 查看卷積層1_1的參數w,b w,b=data_dic[b'conv1_1'] print(w.shape,b.shape) # (3, 3, 3, 64) (64,) # 查看全連接層的參數 w,b=data_dic[b'fc8'] print(w.shape,b.shape) # (4096, 1000) (1000,)
通過將已經訓練好的參數填充到網絡之中就可以搭建VGG網絡了。
在類初始化函數中讀取預訓練模型文件中的參數到self.data_dic
首先構建卷積層,通過傳入的各個卷積層name參數,讀取模型中對應的卷積層參數并填充到網絡中。例如讀取第一個卷積層的權值和偏置值,傳入name='conv1_1,則data_dic[name][0]可以得到權值weight,data_dic[name][1]得到偏置值bias。通過tf.constant構建常量,再執行卷積操作,加偏置項,經激活函數后輸出。
接下來實現池化操作,由于池化不需要參數,所以直接對輸入進行最大池化操作后輸出即可
接著經過展開層,由于卷積池化后的數據是四維向量[batch_size,image_width,image_height,chanel],需要將最后三維展開,將最后三個維度相乘,通過tf.reshape()展開
最后需要把結果經過全連接層,它的實現和卷積層類似,讀取權值和偏置參數后進行全連接操作后輸出。
class VGGNet:
def __init__(self, data_dir):
data = np.load(data_dir, allow_pickle=True, encoding='bytes')
self.data_dic = data.item()
def conv_layer(self, x, name):
# 實現卷積操作
with tf.name_scope(name):
# 從模型文件中讀取各卷積層的參數值
weight = tf.constant(self.data_dic[name][0], name='conv')
bias = tf.constant(self.data_dic[name][1], name='bias')
# 進行卷積操作
y = tf.nn.conv2d(x, weight, [1, 1, 1, 1], padding='SAME')
y = tf.nn.bias_add(y, bias)
return tf.nn.relu(y)
def pooling_layer(self, x, name):
# 實現池化操作
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
def flatten_layer(self, x, name):
# 實現展開層
with tf.name_scope(name):
# x_shape->[batch_size,image_width,image_height,chanel]
x_shape = x.get_shape().as_list()
dimension = 1
# 計算x的最后三個維度積
for d in x_shape[1:]:
dimension *= d
output = tf.reshape(x, [-1, dimension])
return output
def fc_layer(self, x, name, activation=tf.nn.relu):
# 實現全連接層
with tf.name_scope(name):
# 從模型文件中讀取各全連接層的參數值
weight = tf.constant(self.data_dic[name][0], name='fc')
bias = tf.constant(self.data_dic[name][1], name='bias')
# 進行全連接操作
y = tf.matmul(x, weight)
y = tf.nn.bias_add(y, bias)
if activation==None:
return y
else:
return tf.nn.relu(y)
通過self.build()函數實現Vgg16網絡的搭建.數據輸入后首先需要進行歸一化處理,將輸入的RGB數據拆分為R、G、B三個通道,再將三個通道分別減去一個固定值,最后將三通道按B、G、R順序重新拼接為一個新的數據。
接下來則是通過上面的構建函數來搭建VGG網絡,依次將五層的卷積池化網絡、展開層、三個全連接層的參數讀入各層,并搭建起網絡,最后經softmax輸出
def build(self,x_rgb):
s_time=time.time()
# 歸一化處理,在第四維上將輸入的圖片的三通道拆分
r,g,b=tf.split(x_rgb,[1,1,1],axis=3)
# 分別將三通道上減去特定值歸一化后再按bgr順序拼起來
VGG_MEAN = [103.939, 116.779, 123.68]
x_bgr=tf.concat(
[b-VGG_MEAN[0],
g-VGG_MEAN[1],
r-VGG_MEAN[2]],
axis=3
)
# 判別拼接起來的數據是否符合期望,符合再繼續往下執行
assert x_bgr.get_shape()[1:]==[668,668,3]
# 構建各個卷積、池化、全連接等層
self.conv1_1=self.conv_layer(x_bgr,b'conv1_1')
self.conv1_2=self.conv_layer(self.conv1_1,b'conv1_2')
self.pool1=self.pooling_layer(self.conv1_2,b'pool1')
self.conv2_1=self.conv_layer(self.pool1,b'conv2_1')
self.conv2_2=self.conv_layer(self.conv2_1,b'conv2_2')
self.pool2=self.pooling_layer(self.conv2_2,b'pool2')
self.conv3_1=self.conv_layer(self.pool2,b'conv3_1')
self.conv3_2=self.conv_layer(self.conv3_1,b'conv3_2')
self.conv3_3=self.conv_layer(self.conv3_2,b'conv3_3')
self.pool3=self.pooling_layer(self.conv3_3,b'pool3')
self.conv4_1 = self.conv_layer(self.pool3, b'conv4_1')
self.conv4_2 = self.conv_layer(self.conv4_1, b'conv4_2')
self.conv4_3 = self.conv_layer(self.conv4_2, b'conv4_3')
self.pool4 = self.pooling_layer(self.conv4_3, b'pool4')
self.conv5_1 = self.conv_layer(self.pool4, b'conv5_1')
self.conv5_2 = self.conv_layer(self.conv5_1, b'conv5_2')
self.conv5_3 = self.conv_layer(self.conv5_2, b'conv5_3')
self.pool5 = self.pooling_layer(self.conv5_3, b'pool5')
self.flatten=self.flatten_layer(self.pool5,b'flatten')
self.fc6=self.fc_layer(self.flatten,b'fc6')
self.fc7 = self.fc_layer(self.fc6, b'fc7')
self.fc8 = self.fc_layer(self.fc7, b'fc8',activation=None)
self.prob=tf.nn.softmax(self.fc8,name='prob')
print('模型構建完成,用時%d秒'%(time.time()-s_time))
首先需要定義網絡的輸入與輸出。網絡的輸入是風格圖像和內容圖像,兩張圖象都是668×668的3通道圖片。首先通過PIL庫中的Image對象完成讀入內容圖像style_img和風格圖像content_img,并將其轉化為數組,定義對應的占位符style_in和content_in,在訓練時將圖片填入。
網絡的輸出是一張結果圖片668×668的3通道,通過隨機函數初始化一個結果圖像的數組res_out。
利用上面定義的VGGNet類來創建圖片對象,并完成build操作。
vgg16_dir = './data/vgg16_model.npy' style_img = './data/starry_night.jpg' content_img = './data/city_night.jpg' output_dir = './data' def read_image(img): img = Image.open(img) img_np = np.array(img) # 將圖片轉化為[668,668,3]數組 img_np = np.asarray([img_np], ) # 轉化為[1,668,668,3]的數組 return img_np # 輸入風格、內容圖像數組 style_img = read_image(style_img) content_img = read_image(content_img) # 定義對應的輸入圖像的占位符 content_in = tf.placeholder(tf.float32, shape=[1, 668, 668, 3]) style_in = tf.placeholder(tf.float32, shape=[1, 668, 668, 3]) # 初始化輸出的圖像 initial_img = tf.truncated_normal((1, 668, 668, 3), mean=127.5, stddev=20) res_out = tf.Variable(initial_img) # 構建VGG網絡對象 res_net = VGGNet(vgg16_dir) style_net = VGGNet(vgg16_dir) content_net = VGGNet(vgg16_dir) res_net.build(res_out) style_net.build(style_in) content_net.build(content_in)
接著需要定義損失函數loss。
對于內容損失,先選定內容風格圖像和結果圖像的卷積層,要相同,比如這里選取了卷積層1_1和2_1。然后這兩個特征層的后三個通道求平方差,然后取均值,就是內容損失。
對于風格損失,首先需要對風格圖像和結果圖像的特征層求gram矩陣,然后對gram矩陣求平方差的均值。
最后按照系數比例將兩個損失函數相加即可得到loss
# 計算損失,分別需要計算內容損失和風格損失 # 提取內容圖像的內容特征 content_features = [ content_net.conv1_2, content_net.conv2_2 # content_net.conv2_2 ] # 對應結果圖像提取相同層的內容特征 res_content = [ res_net.conv1_2, res_net.conv2_2 # res_net.conv2_2 ] # 計算內容損失 content_loss = tf.zeros(1, tf.float32) for c, r in zip(content_features, res_content): content_loss += tf.reduce_mean((c - r) ** 2, [1, 2, 3]) # 計算風格損失的gram矩陣 def gram_matrix(x): b, w, h, ch = x.get_shape().as_list() features = tf.reshape(x, [b, w * h, ch]) # 對features矩陣作內積,再除以一個常數 gram = tf.matmul(features, features, adjoint_a=True) / tf.constant(w * h * ch, tf.float32) return gram # 對風格圖像提取特征 style_features = [ # style_net.conv1_2 style_net.conv4_3 ] style_gram = [gram_matrix(feature) for feature in style_features] # 提取結果圖像對應層的風格特征 res_features = [ res_net.conv4_3 ] res_gram = [gram_matrix(feature) for feature in res_features] # 計算風格損失 style_loss = tf.zeros(1, tf.float32) for s, r in zip(style_gram, res_gram): style_loss += tf.reduce_mean((s - r) ** 2, [1, 2]) # 模型內容、風格特征的系數 k_content = 0.1 k_style = 500 # 按照系數將兩個損失值相加 loss = k_content * content_loss + k_style * style_loss
接下來開始進行100輪的訓練,打印并查看過程中的總損失、內容損失、風格損失值。并將每輪的生成結果圖片輸出到指定目錄下
# 進行訓練
learning_steps = 100
learning_rate = 10
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(learning_steps):
t_loss, c_loss, s_loss, _ = sess.run(
[loss, content_loss, style_loss, train_op],
feed_dict={content_in: content_img, style_in: style_img}
)
print('第%d輪訓練,總損失:%.4f,內容損失:%.4f,風格損失:%.4f'
% (i + 1, t_loss[0], c_loss[0], s_loss[0]))
# 獲取結果圖像數組并保存
res_arr = res_out.eval(sess)[0]
res_arr = np.clip(res_arr, 0, 255) # 將結果數組中的值裁剪到0~255
res_arr = np.asarray(res_arr, np.uint8) # 將圖片數組轉化為uint8
img_path = os.path.join(output_dir, 'res_%d.jpg' % (i + 1))
# 圖像數組轉化為圖片
res_img = Image.fromarray(res_arr)
res_img.save(img_path)
運行結果如下可以看到依次分別為內容圖片、風格圖片、訓練12輪、46輪、100輪結果圖片





更多關于Python相關內容感興趣的讀者可查看本站專題:《Python數據結構與算法教程》、《Python加密解密算法與技巧總結》、《Python編碼操作技巧總結》、《Python函數使用技巧總結》、《Python字符串操作技巧匯總》及《Python入門與進階經典教程》
希望本文所述對大家Python程序設計有所幫助。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





