溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在上篇博客中,我們已經實現了水平投影和垂直投影圖的繪制。接下來,我們可以根據獲得的投影數據進行圖像的分割,該法用于文本分割較多,所以此處依然以上次的圖為例。
先把上次的兩幅圖搬過來,方便講解。
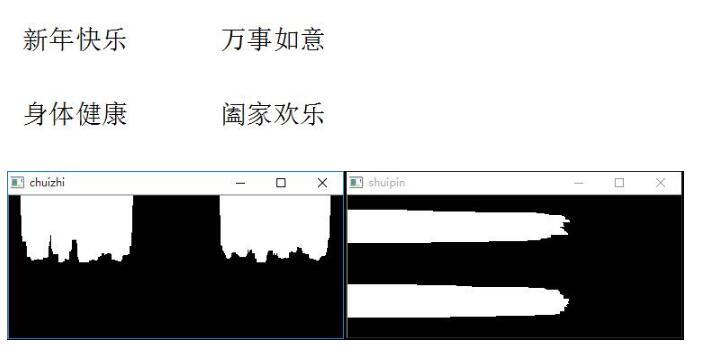
上面兩圖分別從垂直和水平方向描述了圖像中文本的分布。我們想象一下,將兩幅圖重疊起來(當然這里比例要調整下),那么我們就能得到四個重疊的白塊,而這些白塊所處的位置正是原圖中文本的位置。所以接下來的任務就是,找出這些白塊的坐標,此處白塊近似矩形,所以我們要求矩形的四個坐標。
下面看代碼。
#根據水平投影值選定行分割點
inline = 1
start = 0
j = 0
for i in range(0,height):
if inline == 1 and z[i] >= 150 : #從空白區進入文字區
start = i #記錄起始行分割點
print i
inline = 0
elif (i - start > 3) and z[i] < 150 and inline == 0 : #從文字區進入空白區
inline = 1
hfg[j][0] = start - 2 #保存行分割位置
hfg[j][1] = i + 2
j = j + 1
確定行分割點的原理就是判斷每一行的像素點數是否足夠。我們可以從水平投影圖中看出,白塊是有文字的地方(原圖是黑字白底,只是畫投影圖時選用白塊黑底),即前面幾行,灰度值為0的點的個數N很少,所以當遇到文字區時,N會很大,根據這一點,我們確定進入文字區的坐標(A1,B1)。然后,當從文字區出來時,N又變的很小,我們再記下它的坐標(A1,B2)。同理,我們可以確定列分割點。
incol = 1
start1 = 0
j1 = 0
z1 = hfg[p][0]
z2 = hfg[p][1]
for i1 in range(0,width):
if incol == 1 and v[i1] >= 20 : #從空白區進入文字區
start1 = i1 #記錄起始列分割點
incol = 0
elif (i1 - start1 > 3) and v[i1] < 20 and incol == 0 : #從文字區進入空白區
incol = 1
lfg[j1][0] = start1 - 2 #保存列分割位置
lfg[j1][1] = i1 + 2
l1 = start1 - 2
l2 = i1 + 2
j1 = j1 + 1
最后根據矩形的坐標將文本在圖中框出來。附上完整代碼。
import cv2
import numpy
img = cv2.imread('D:/0.jpg',cv2.COLOR_BGR2GRAY)
height, width = img.shape[:2]
#print height, width
#resized = cv2.resize(img, (2*width,2*height), interpolation=cv2.INTER_CUBIC)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
(_, thresh) = cv2.threshold(gray, 140, 255, cv2.THRESH_BINARY)
#使文字增長成塊
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))#形態學處理,定義矩形結構
closed = cv2.erode(thresh, None, iterations = 7)
#cv2.imshow('erode',closed)
height, width = closed.shape[:2]
#print height, width
z = [0]*height
v = [0]*width
hfg = [[0 for col in range(2)] for row in range(height)]
lfg = [[0 for col in range(2)] for row in range(width)]
box = [0,0,0,0]
#水平投影
a = 0
emptyImage1 = numpy.zeros((height, width, 3), numpy.uint8)
for y in range(0, height):
for x in range(0, width):
cp = closed[y,x]
#if np.any(closed[y,x]):
if cp == 0:
a = a + 1
else :
continue
z[y] = a
#print z[y]
a = 0
#根據水平投影值選定行分割點
inline = 1
start = 0
j = 0
for i in range(0,height):
if inline == 1 and z[i] >= 150 : #從空白區進入文字區
start = i #記錄起始行分割點
#print i
inline = 0
elif (i - start > 3) and z[i] < 150 and inline == 0 : #從文字區進入空白區
inline = 1
hfg[j][0] = start - 2 #保存行分割位置
hfg[j][1] = i + 2
j = j + 1
#對每一行垂直投影、分割
a = 0
for p in range(0, j):
for x in range(0, width):
for y in range(hfg[p][0], hfg[p][1]):
cp1 = closed[y,x]
if cp1 == 0:
a = a + 1
else :
continue
v[x] = a #保存每一列像素值
a = 0
#print width
#垂直分割點
incol = 1
start1 = 0
j1 = 0
z1 = hfg[p][0]
z2 = hfg[p][1]
for i1 in range(0,width):
if incol == 1 and v[i1] >= 20 : #從空白區進入文字區
start1 = i1 #記錄起始列分割點
incol = 0
elif (i1 - start1 > 3) and v[i1] < 20 and incol == 0 : #從文字區進入空白區
incol = 1
lfg[j1][0] = start1 - 2 #保存列分割位置
lfg[j1][1] = i1 + 2
l1 = start1 - 2
l2 = i1 + 2
j1 = j1 + 1
cv2.rectangle(img, (l1, z1), (l2, z2), (255,0,0), 2)
cv2.imshow('result', img)
cv2.waitKey(0)
代碼中注釋掉的一些代碼,有的是我做的一些小變動,有的是觀察中間值。大家可自行查看。
最后放上結果圖。

由于文本的坐標已經有了,還可以把這些文本塊截取下來,用一下PIL或者OPENCV就好了,此處就不做了。
以上這篇Python實現投影法分割圖像示例(二)就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





