溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何在python中使用jieba中文分詞庫,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
1.1、CUT函數簡介
cut(sentence, cut_all=False, HMM=True)
返回生成器,遍歷生成器即可獲得分詞的結果
lcut(sentence)
返回分詞列表
import jieba sentence = '我愛自然語言處理' # 創建【Tokenizer.cut 生成器】對象 generator = jieba.cut(sentence) # 遍歷生成器,打印分詞結果 words = '/'.join(generator) print(words)
打印結果
我/愛/自然語言/處理
import jieba
print(jieba.lcut('我愛南海中學'))打印結果
[‘我', ‘愛', ‘南海中學']
1.2、分詞模式
精確模式:精確地切開
全模式:所有可能的詞語都切出,速度快
搜索引擎模式:在精確模式的基礎上,對長詞再次切分
import jieba
sentence = '訂單數據分析'
print('精準模式:', jieba.lcut(sentence))
print('全模式:', jieba.lcut(sentence, cut_all=True))
print('搜索引擎模式:', jieba.lcut_for_search(sentence))打印結果
精準模式: [‘訂單', ‘數據分析']
全模式: [‘訂單', ‘訂單數', ‘單數', ‘數據', ‘數據分析', ‘分析']
搜索引擎模式: [‘訂單', ‘數據', ‘分析', ‘數據分析']
1.3、詞性標注
jieba.posseg import jieba.posseg as jp sentence = '我愛Python數據分析' posseg = jp.cut(sentence) for i in posseg: print(i.__dict__) # print(i.word, i.flag)
打印結果
{‘word': ‘我', ‘flag': ‘r'}
{‘word': ‘愛', ‘flag': ‘v'}
{‘word': ‘Python', ‘flag': ‘eng'}
{‘word': ‘數據分析', ‘flag': ‘l'}詞性標注表
| 標注 | 解釋 | 標注 | 解釋 | 標注 | 解釋 |
|---|---|---|---|---|---|
| a | 形容詞 | mq | 數量詞 | tg | 時語素 |
| ad | 副形詞 | n | 名詞 | u | 助詞 |
| ag | 形語素 | ng | 例:義 乳 亭 | ud | 例:得 |
| an | 名形詞 | nr | 人名 | ug | 例:過 |
| b | 區別詞 | nrfg | 也是人名 | uj | 例:的 |
| c | 連詞 | nrt | 也是人名 | ul | 例:了 |
| d | 副詞 | ns | 地名 | uv | 例:地 |
| df | 例:不要 | nt | 機構團體 | uz | 例:著 |
| dg | 副語素 | nz | 其他專名 | v | 動詞 |
| e | 嘆詞 | o | 擬聲詞 | vd | 副動詞 |
| f | 方位詞 | p | 介詞 | vg | 動語素 |
| g | 語素 | q | 量詞 | vi | 例:沉溺于 等同于 |
| h | 前接成分 | r | 代詞 | vn | 名動詞 |
| i | 成語 | rg | 例:茲 | vq | 例:去浄 去過 唸過 |
| j | 簡稱略語 | rr | 人稱代詞 | x | 非語素字 |
| k | 后接成分 | rz | 例:這位 | y | 語氣詞 |
| l | 習用語 | s | 處所詞 | z | 狀態詞 |
| m | 數詞 | t | 時間詞 | zg | 例:且 丗 丟 |
1.4、詞語出現的位置
jieba.tokenize(sentence) import jieba sentence = '訂單數據分析' generator = jieba.tokenize(sentence) for position in generator: print(position)
打印結果
(‘訂單', 0, 2) (‘數據分析', 2, 6)
2.1、默認詞典
import jieba, os, pandas as pd
# 詞典所在位置
print(jieba.__file__)
jieba_dict = os.path.dirname(jieba.__file__) + r'\dict.txt'
# 讀取字典
df = pd.read_table(jieba_dict, sep=' ', header=None)[[0, 2]]
print(df.head())
# 轉字典
dt = dict(df.values)
print(dt.get('暨南大學'))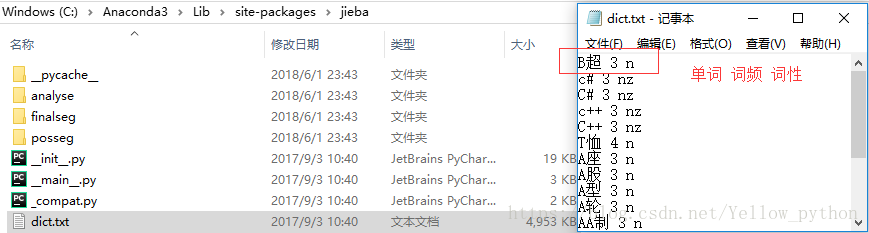
2.2、添詞和刪詞
往詞典添詞
add_word(word, freq=None, tag=None)
往詞典刪詞,等價于add_word(word, freq=0)
del_word(word)
import jieba
sentence = '天長地久有時盡,此恨綿綿無絕期'
# 添詞
jieba.add_word('時盡', 999, 'nz')
print('添加【時盡】:', jieba.lcut(sentence))
# 刪詞
jieba.del_word('時盡')
print('刪除【時盡】:', jieba.lcut(sentence))打印結果
添加【時盡】: [‘天長地久', ‘有', ‘時盡', ‘,', ‘此恨綿綿', ‘無', ‘絕期']
刪除【時盡】: [‘天長地久', ‘有時', ‘盡', ‘,', ‘此恨綿綿', ‘無', ‘絕期']
2.3、自定義詞典加載
新建詞典,按照格式【單詞 詞頻 詞性】添詞,以UTF-8編碼保存
使用函數load_userdict加載詞典
import os, jieba
# 創建自定義字典
my_dict = 'my_dict.txt'
with open(my_dict, 'w', encoding='utf-8') as f:
f.write('慕容紫英 9 nr\n云天河 9 nr\n天河劍 9 nz')
# 加載字典進行測試
sentence = '慕容紫英為云天河打造了天河劍'
print('加載前:', jieba.lcut(sentence))
jieba.load_userdict(my_dict)
print('加載后:', jieba.lcut(sentence))
os.remove(my_dict)打印結果
加載前: [‘慕容', ‘紫英為', ‘云', ‘天河', ‘打造', ‘了', ‘天河', ‘劍']
加載后: [‘慕容紫英', ‘為', ‘云天河', ‘打造', ‘了', ‘天河劍']
2.4、使單詞中的字符連接或拆分
suggest_freq(segment, tune=False)
import jieba
sentence = '上窮碧落下黃泉,兩處茫茫皆不見'
print('修正前:', ' | '.join(jieba.cut(sentence)))
jieba.suggest_freq(('落', '下'), True)
print('修正后:', ' | '.join(jieba.cut(sentence)))打印結果
修正前: 上窮 | 碧 | 落下 | 黃泉 | , | 兩處 | 茫茫 | 皆 | 不見
修正后: 上窮 | 碧落 | 下 | 黃泉 | , | 兩處 | 茫茫 | 皆 | 不見
基于詞典,對句子進行詞圖掃描,生成所有成詞情況所構成的有向無環圖(Directed Acyclic Graph)
根據DAG,反向計算最大概率路徑(動態規劃算法;取對數防止下溢,乘法運算轉為加法)
根據路徑獲取最大概率的分詞序列
import jieba
sentence = '中心小學放假'
DAG = jieba.get_DAG(sentence)
print(DAG)
route = {}
jieba.calc(sentence, DAG, route)
print(route)DAG
{0: [0, 1, 3], 1: [1], 2: [2, 3], 3: [3], 4: [4, 5], 5: [5]}
最大概率路徑
{6: (0, 0), 5: (-9.4, 5), 4: (-12.6, 5), 3: (-20.8, 3), 2: (-22.5, 3), 1: (-30.8, 1), 0: (-29.5, 3)}
示例:使Blade Master這類中間有空格的詞被識別
import jieba, re
sentence = 'Blade Master疾風刺殺Archmage'
jieba.add_word('Blade Master') # 添詞
print('修改前:', jieba.lcut(sentence))
jieba.re_han_default = re.compile('(.+)', re.U) # 修改格式
print('修改后:', jieba.lcut(sentence))打印結果
修改前: [‘Blade', ' ', ‘Master', ‘疾風', ‘刺殺', ‘Archmage']
修改后: [‘Blade Master', ‘疾風', ‘刺殺', ‘Archmage']
5.1、并行分詞
運行環境:linux系統
開啟并行分詞模式,參數n為并發數:jieba.enable_parallel(n)
關閉并行分詞模式:jieba.disable_parallel()
5.2、關鍵詞提取
基于TF-IDF:jieba.analyse
基于TextRank:jieba.textrank
import jieba.analyse as ja, jieba
text = '柳夢璃施法破解了狐仙的法術'
jieba.add_word('柳夢璃', tag='nr')
keywords1 = ja.extract_tags(text, allowPOS=('n', 'nr', 'ns', 'nt', 'nz'))
print('基于TF-IDF:', keywords1)
keywords2 = ja.textrank(text, allowPOS=('n', 'nr', 'ns', 'nt', 'nz'))
print('基于TextRank:', keywords2)打印結果
基于TF-IDF: [‘柳夢璃', ‘狐仙', ‘法術']
基于TextRank: [‘狐仙', ‘柳夢璃', ‘法術']
5.3、修改HMM參數
import jieba
text = '柳夢璃解夢C法'
print(jieba.lcut(text, HMM=False)) # ['柳', '夢', '璃', '解夢', 'C', '法']
print(jieba.lcut(text)) # ['柳夢璃', '解夢', 'C', '法']
jieba.finalseg.emit_P['B']['C'] = -1e-9 # begin
print(jieba.lcut(text)) # ['柳夢璃', '解夢', 'C', '法']
jieba.finalseg.emit_P['M']['夢'] = -100 # middle
print(jieba.lcut(text)) # ['柳', '夢璃', '解夢', 'C', '法']
jieba.finalseg.emit_P['S']['夢'] = -.1 # single
print(jieba.lcut(text)) # ['柳', '夢', '璃', '解夢', 'C', '法']
jieba.finalseg.emit_P['E']['夢'] = -.01 # end
print(jieba.lcut(text)) # ['柳夢', '璃', '解夢', 'C', '法']
jieba.del_word('柳夢') # Force_Split_Words
print(jieba.lcut(text)) # ['柳', '夢', '璃', '解夢', 'C', '法'][‘柳', ‘夢', ‘璃', ‘解夢', ‘C', ‘法']
[‘柳夢璃', ‘解夢', ‘C', ‘法']
[‘柳夢璃', ‘解夢', ‘C', ‘法']
[‘柳', ‘夢璃', ‘解夢', ‘C', ‘法']
[‘柳', ‘夢', ‘璃', ‘解夢', ‘C', ‘法']
[‘柳夢', ‘璃', ‘解夢', ‘C', ‘法']
[‘柳', ‘夢', ‘璃', ‘解夢', ‘C', ‘法']
以上就是如何在python中使用jieba中文分詞庫,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





