溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關怎么在python中實現數據降維,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
python的數據類型:1. 數字類型,包括int(整型)、long(長整型)和float(浮點型)。2.字符串,分別是str類型和unicode類型。3.布爾型,Python布爾類型也是用于邏輯運算,有兩個值:True(真)和False(假)。4.列表,列表是Python中使用最頻繁的數據類型,集合中可以放任何數據類型。5. 元組,元組用”()”標識,內部元素用逗號隔開。6. 字典,字典是一種鍵值對的集合。7. 集合,集合是一個無序的、不重復的數據組合。
數據為何要降維
數據降維可以降低模型的計算量并減少模型運行時間、降低噪音變量信息對于模型結果的影響、便于通過可視化方式展示歸約后的維度信息并減少數據存儲空間。因此,大多數情況下,當我們面臨高維數據時,都需要對數據做降維處理。
數據降維有兩種方式:特征選擇,維度轉換
特征選擇
特征選擇指根據一定的規則和經驗,直接在原有的維度中挑選一部分參與到計算和建模過程,用選擇的特征代替所有特征,不改變原有特征,也不產生新的特征值。
特征選擇的降維方式好處是可以保留原有維度特征的基礎上進行降維,既能滿足后續數據處理和建模需求,又能保留維度原本的業務含義,以便于業務理解和應用。對于業務分析性的應用而言,模型的可理解性和可用性很多時候要有限于模型本身的準確率、效率等技術指標。例如,決策樹得到的特征規則,可以作為選擇用戶樣本的基礎條件,而這些特征規則便是基于輸入的維度產生。
維度轉換
這個是按照一定數學變換方法,把給定的一組相關變量(維度)通過數學模型將高緯度空間的數據點映射到低緯度空間中,然后利用映射后變量的特征來表示原有變量的總體特征。這種方式是一種產生新維度的過程,轉換后的維度并非原來特征,而是之前特征的轉化后的表達式,新的特征丟失了原有數據的業務含義。 通過數據維度變換的降維方法是非常重要的降維方法,這種降維方法分為線性降維和非線性降維兩種,其中常用的代表算法包括獨立成分分析(ICA),主成分分析(PCA),因子分析(Factor Analysis,FA),線性判別分析(LDA),局部線性嵌入(LLE),核主成分分析(Kernel PCA)等。
使用python做降維處理
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.decomposition import PCA
# 數據導入
df = pd.read_csv('https://raw.githubusercontent.com/ffzs/dataset/master/glass.csv')
# 看一下數據是
df.head()
RI Na Mg Al Si K Ca Ba Fe Type
0 1.52101 13.64 4.49 1.10 71.78 0.06 8.75 0.0 0.0 1
1 1.51761 13.89 3.60 1.36 72.73 0.48 7.83 0.0 0.0 1
2 1.51618 13.53 3.55 1.54 72.99 0.39 7.78 0.0 0.0 1
3 1.51766 13.21 3.69 1.29 72.61 0.57 8.22 0.0 0.0 1
4 1.51742 13.27 3.62 1.24 73.08 0.55 8.07 0.0 0.0 1
# 有無缺失值
df.isna().values.any()
# False 沒有缺失值
# 獲取特征值
X = df.iloc[:, :-1].values
# 獲取標簽值
Y = df.iloc[:,[-1]].values
# 使用sklearn 的DecisionTreeClassifier判斷變量重要性
# 建立分類決策樹模型對象
dt_model = DecisionTreeClassifier(random_state=1)
# 將數據集的維度和目標變量輸入模型
dt_model.fit(X, Y)
# 獲取所有變量的重要性
feature_importance = dt_model.feature_importances_
feature_importance
# 結果如下
# array([0.20462132, 0.06426227, 0.16799114, 0.15372793, 0.07410088, 0.02786222, 0.09301948, 0.16519298, 0.04922178])
# 做可視化
import matplotlib.pyplot as plt
x = range(len(df.columns[:-1]))
plt.bar(left= x, height=feature_importance)
plt.xticks(x, df.columns[:-1])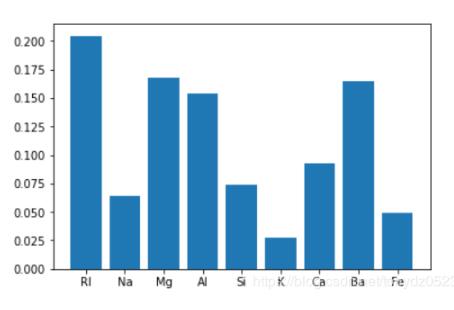
可見Rl、Mg、Al、Ba的重要性比較高,一般情況下變量重要性得分接近80%,基本上已經可以解釋大部分的特征變化。
PCA降維
# 使用sklearn的PCA進行維度轉換 # 建立PCA模型對象 n_components控制輸出特征個數 pca_model = PCA(n_components=3) # 將數據集輸入模型 pca_model.fit(X) # 對數據集進行轉換映射 pca_model.transform(X) # 獲得轉換后的所有主成分 components = pca_model.components_ # 獲得各主成分的方差 components_var = pca_model.explained_variance_ # 獲取主成分的方差占比 components_var_ratio = pca_model.explained_variance_ratio_ # 打印方差 print(np.round(components_var,3)) # [3.002 1.659 0.68 ] # 打印方差占比 print(np.round(components_var_ratio,3)) # [0.476 0.263 0.108]
看完上述內容,你們對怎么在python中實現數據降維有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





