溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python中使用ElementTree可以很方便的處理XML,但是產生的XML文件內容會合并在一行,難以看清楚。
如下格式:
<root><aa>aatext<cc>cctext</cc></aa><bb>bbtext<dd>ddtext<ee>eetext</ee></dd></bb></root>
使用minidom模塊中的toprettyxml和writexml方法都有參數可以優化XML,但是有兩個問題:
a. 如果解析的XML已經是美化過的,那么執行該方法會多出很多空行
b. 產生的結果會將text也獨立一行,如下:
<root>
<aa>
aatext
</aa>
<bb>
bbtext
</bb>
</root>
而我想產生如下結果:
<root> <aa>aatext</aa> <bb>bbtext</bb> </root>
于是只能自己寫一個美化XML的方法。
我們首先研究一下ElementTree模塊中的Element類,使用getroot方法返回的便是Element類。
該類中有四個屬性tag、attrib、text與tail, 對應在XML中如下圖所示:

整個XML就是一個Element,里面嵌套了很多子Element。
Element可以使用for循環迭代。
通過在text和tail中增加換行和制表符,就可以實現美化XML的目的。
美化代碼如下:
def prettyXml(element, indent, newline, level = 0): # elemnt為傳進來的Elment類,參數indent用于縮進,newline用于換行
if element: # 判斷element是否有子元素
if element.text == None or element.text.isspace(): # 如果element的text沒有內容
element.text = newline + indent * (level + 1)
else:
element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * (level + 1)
#else: # 此處兩行如果把注釋去掉,Element的text也會另起一行
#element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * level
temp = list(element) # 將elemnt轉成list
for subelement in temp:
if temp.index(subelement) < (len(temp) - 1): # 如果不是list的最后一個元素,說明下一個行是同級別元素的起始,縮進應一致
subelement.tail = newline + indent * (level + 1)
else: # 如果是list的最后一個元素, 說明下一行是母元素的結束,縮進應該少一個
subelement.tail = newline + indent * level
prettyXml(subelement, indent, newline, level = level + 1) # 對子元素進行遞歸操作
from xml.etree import ElementTree #導入ElementTree模塊
tree = ElementTree.parse('test.xml') #解析test.xml這個文件,該文件內容如上文
root = tree.getroot() #得到根元素,Element類
prettyXml(root, '\t', '\n') #執行美化方法
ElementTree.dump(root) #顯示出美化后的XML內容
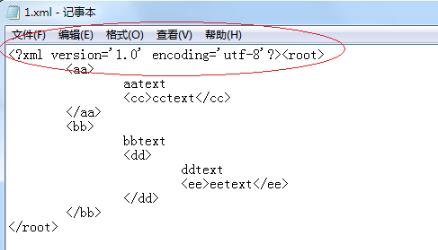
輸出結果如下:
<root>
<aa>
aatext
<cc>cctext</cc>
</aa>
<bb>
bbtext
<dd>
ddtext
<ee>eetext</ee>
</dd>
</bb>
</root>
殘留問題點:
windows下的換行符是"\r\n",只需將prettyXml方法的第三個參數改為"\r\n",使用記事本打開生成的XML大部分OK。
但是XML說明與根元素開始符之間不知如何插入"\r\n".
補充知識:python-xml 模塊-代碼生成xml 文檔
一、XML 模塊
什么是xml:可擴展的標記語言,標記翻譯為標簽,用標簽來組織數據的語言,也是一種語言可以用來自定義文檔結構。相比json 使用場景更加廣泛,但是語法格式相比json 復雜很多
什么時候使用json:前后臺交互數據時使用json
什么時候使用xml:當需要自定義文檔結構時使用xml,比如java中經常用xml來作為配置文件,常見操作就是通過程序去讀取配置信息,而修改增加刪除,一般是交給用戶來手動完成
標簽的叫發:node(節點)、elment(元素)、tag(標簽)
需求從conuntrys中獲取所有的國家名稱
==========================>countrys
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2009</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2012</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2012</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data># 取別名可以用于簡化書寫
import xml.etree.ElementTree as ET
tree = ET.parse('countrys')
#獲取根標簽#第一種獲取標簽的方式
#全文查找
iter()
# 獲取迭代器 如果不指定參數 則迭代器迭代的是所有標簽
print(root.iter())
# 獲取迭代器 如果指定參數 則迭代器迭代的是所有名稱匹配的標簽
for e in root.iter("rank"):
print(e)
#第二種獲取標簽的方式
#在當前標簽下(所有子級標簽)尋找第一個名稱匹配的標簽
print(root.find("rank")) #第一個名稱不匹配所以返回None#第三種獲取標簽的方式
#在當前標簽下(所有子級標簽)尋找所有名稱匹配的標簽
print(root.findall("rank")) #[]
練習:找到新加坡中year 這個標簽
#print(e.tag) #標簽名稱
#print(e.attrib) #屬性 字典類型
#print(e.text) #文本內容import xml.etree.ElementTree as ETtree = ET.parse("countrys")
# 獲取根標簽
root = tree.getroot()
for e in root.iter("country"):
if e.attrib["name"] == "Singapore":
y = e.find("year")
print(y.text) #2012
在程序中修改文檔內容:把所有year標簽的文本加1
import xml.etree.ElementTree as ETtree = ET.parse("countrys")
root = tree.getroot()
for e in root.iter("year"):
e.text = str(int(e.text) + 1)
#做完修改后要將修改后的內容寫入文件
tree.write('countrys')
把新加坡國家刪除:
import xml.etree.ElementTree as ETtree = ET.parse("countrys")
root = tree.getroot()for e in root.findall("country"):
print(e)
if e.attrib["name"] == "Singapore":
#刪除時要通過被刪除的父級標簽來刪除
root.remove(e)tree.write('countrys')
用程序將中國信息寫入文檔中:
import xml.etree.ElementTree as ETtree = ET.parse("countrys")
root = tree.getroot()
#添加時也需要將要添加的數據做成一個Element
c = ET.Element("country",{"name":"china"})# 在國家下有一堆子標簽
ranke = ET.Element("ranke",{"updated":"yes"})
c.append(ranke)year = ET.Element("year")
year.text = "2018"
c.append(year)#添加到root標簽中
root.append(c)
tree.write("countrys")
總結:一般不會通過程序 去修改 刪除 和添加
什么時候應該使用XML格式:
當你需要自定文檔結構時(XML最強大的地方就是結構)
前后臺交互不應該使用,前后臺交互應該使用JSON格式
代碼生成XML文檔
import xml.etree.ElementTree as ET# 創建根標簽
root = ET.Element("root")
root.text = "這是一個XML文檔!"c = ET.Element("country",{"name":"china"})
root.append(c)tree = ET.ElementTree(root)
# 參數: 文件名稱 編碼方式 是否需要文檔聲明
tree.write("new.xml",encoding="utf-8",xml_declaration=True)=========================>new.xml 內容為
<?xml version='1.0' encoding='utf-8'?>
<root>這是一個XML文檔!<country name="china" /></root>
以上這篇Python使用ElementTree美化XML格式的操作就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





