溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
不懂sklearn對多分類的每個類別進行指標評價方法?其實想解決這個問題也不難,下面讓小編帶著大家一起學習怎么去解決,希望大家閱讀完這篇文章后大所收獲。
對多分類結果的每個類別進行指標評價,也就是需要輸出每個類型的精確率(precision),召回率(recall)以及F1值(F1-score)。
我們可以用sklearn來解決,方法并沒有難,我們模擬的數據如下:
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
其中y_true為真實數據,y_pred為多分類后的模擬數據。使用sklearn.metrics中的classification_report即可實現對多分類的每個類別進行指標評價。
示例的Python代碼如下:
# -*- coding: utf-8 -*- from sklearn.metrics import classification_report y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海'] y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海'] t = classification_report(y_true, y_pred, target_names=['北京', '上海', '成都']) print(t)
輸出結果如下:
precision recall f1-score support
北京 0.75 0.75 0.75 4
上海 1.00 0.67 0.80 3
成都 0.50 0.67 0.57 3
accuracy 0.70 10
macro avg 0.75 0.69 0.71 10
weighted avg 0.75 0.70 0.71 10需要注意的是,輸出的結果數據類型為str,如果需要使用該輸出結果,則可將該方法中的output_dict參數設置為True,此時輸出的結果如下:
{‘北京': {‘precision': 0.75, ‘recall': 0.75, ‘f1-score': 0.75, ‘support': 4},
‘上海': {‘precision': 1.0, ‘recall': 0.6666666666666666, ‘f1-score': 0.8, ‘support': 3},
‘成都': {‘precision': 0.5, ‘recall': 0.6666666666666666, ‘f1-score': 0.5714285714285715, ‘support': 3},
‘accuracy': 0.7,
‘macro avg': {‘precision': 0.75, ‘recall': 0.6944444444444443, ‘f1-score': 0.7071428571428572, ‘support': 10},
‘weighted avg': {‘precision': 0.75, ‘recall': 0.7, ‘f1-score': 0.7114285714285715, ‘support': 10}}使用confusion_matrix方法可以輸出該多分類問題的混淆矩陣,代碼如下:
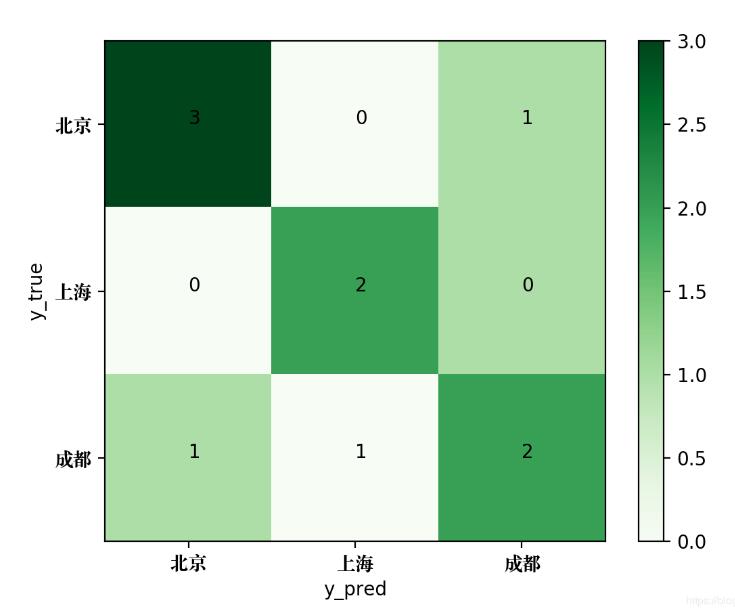
from sklearn.metrics import confusion_matrix y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海'] y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海'] print(confusion_matrix(y_true, y_pred, labels = ['北京', '上海', '成都']))
輸出結果如下:
[[2 0 1] [0 3 1] [0 1 2]]
為了將該混淆矩陣繪制成圖片,可使用如下的Python代碼:
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Daxing Beijing
# time: 2019-11-14 21:52
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import matplotlib as mpl
# 支持中文字體顯示, 使用于Mac系統
zhfont=mpl.font_manager.FontProperties(fname="/Library/Fonts/Songti.ttc")
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
classes = ['北京', '上海', '成都']
confusion = confusion_matrix(y_true, y_pred)
# 繪制熱度圖
plt.imshow(confusion, cmap=plt.cm.Greens)
indices = range(len(confusion))
plt.xticks(indices, classes, fontproperties=zhfont)
plt.yticks(indices, classes, fontproperties=zhfont)
plt.colorbar()
plt.xlabel('y_pred')
plt.ylabel('y_true')
# 顯示數據
for first_index in range(len(confusion)):
for second_index in range(len(confusion[first_index])):
plt.text(first_index, second_index, confusion[first_index][second_index])
# 顯示圖片
plt.show()生成的混淆矩陣圖片如下:
補充知識:python Sklearn實現xgboost的二分類和多分類
二分類:
train2.txt的格式如下:

import numpy as np
import pandas as pd
import sklearn
from sklearn.cross_validation import train_test_split,cross_val_score
from xgboost.sklearn import XGBClassifier
from sklearn.metrics import precision_score,roc_auc_score
min_max_scaler = sklearn.preprocessing.MinMaxScaler(feature_range=(-1,1))
resultX = []
resultY = []
with open("./train_data/train2.txt",'r') as rf:
train_lines = rf.readlines()
for train_line in train_lines:
train_line_temp = train_line.split(",")
train_line_temp = map(float, train_line_temp)
line_x = train_line_temp[1:-1]
line_y = train_line_temp[-1]
resultX.append(line_x)
resultY.append(line_y)
X = np.array(resultX)
Y = np.array(resultY)
X = min_max_scaler.fit_transform(X)
X_train,X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.3)
xgbc = XGBClassifier()
xgbc.fit(X_train,Y_train)
pre_test = xgbc.predict(X_test)
auc_score = roc_auc_score(Y_test,pre_test)
pre_score = precision_score(Y_test,pre_test)
print("xgb_auc_score:",auc_score)
print("xgb_pre_score:",pre_score)多分類:有19種分類其中正常0,異常1~18種。數據格式如下:

# -*- coding:utf-8 -*-
from sklearn import datasets
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import LinearSVC
from sklearn.cross_validation import train_test_split,cross_val_score
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from xgboost.sklearn import XGBClassifier
import sklearn
import numpy as np
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import precision_score,roc_auc_score
min_max_scaler = sklearn.preprocessing.MinMaxScaler(feature_range=(-1,1))
resultX = []
resultY = []
with open("../train_data/train_multi_class.txt",'r') as rf:
train_lines = rf.readlines()
for train_line in train_lines:
train_line_temp = train_line.split(",")
train_line_temp = map(float, train_line_temp) # 轉化為浮點數
line_x = train_line_temp[1:-1]
line_y = train_line_temp[-1]
resultX.append(line_x)
resultY.append(line_y)
X = np.array(resultX)
Y = np.array(resultY)
#fit_transform(partData)對部分數據先擬合fit,找到該part的整體指標,如均值、方差、最大值最小值等等(根據具體轉換的目的),然后對該partData進行轉換transform,從而實現數據的標準化、歸一化等等。。
X = min_max_scaler.fit_transform(X)
#通過OneHotEncoder函數將Y值離散化成19維,例如3離散成000000···100
Y = OneHotEncoder(sparse = False).fit_transform(Y.reshape(-1,1))
X_train,X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.2)
model = OneVsRestClassifier(XGBClassifier(),n_jobs=2)
clf = model.fit(X_train, Y_train)
pre_Y = clf.predict(X_test)
test_auc2 = roc_auc_score(Y_test,pre_Y)#驗證集上的auc值
print ("xgb_muliclass_auc:",test_auc2)感謝你能夠認真閱讀完這篇文章,希望小編分享sklearn對多分類的每個類別進行指標評價方法內容對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,遇到問題就找億速云,詳細的解決方法等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





