溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Linux中的Cache Memory是什么?針對這個問題,這篇文章給出了相對應的分析和解答,希望能幫助更多想解決這個問題的朋友找到更加簡單易行的辦法。
在思考cache是什么之前我們首先先來思考第一個問題:我們的程序是如何運行起來的?我們應該知道程序是運行在 RAM之中,RAM 就是我們常說的DDR(例如 DDR3、DDR4等)。我們稱之為main memory(主存)當我們需要運行一個進程的時候,首先會從Flash設備(例如,eMMC、UFS等)中將可執行程序load到main memory中,然后開始執行。在CPU內部存在一堆的通用寄存器(register)。如果CPU需要將一個變量(假設地址是A)加1,一般分為以下3個步驟:
CPU 從主存中讀取地址A的數據到內部通用寄存器 x0(ARM64架構的通用寄存器之一)。
通用寄存器 x0 加1。
CPU 將通用寄存器 x0 的值寫入主存。
我們將這個過程可以表示如下:
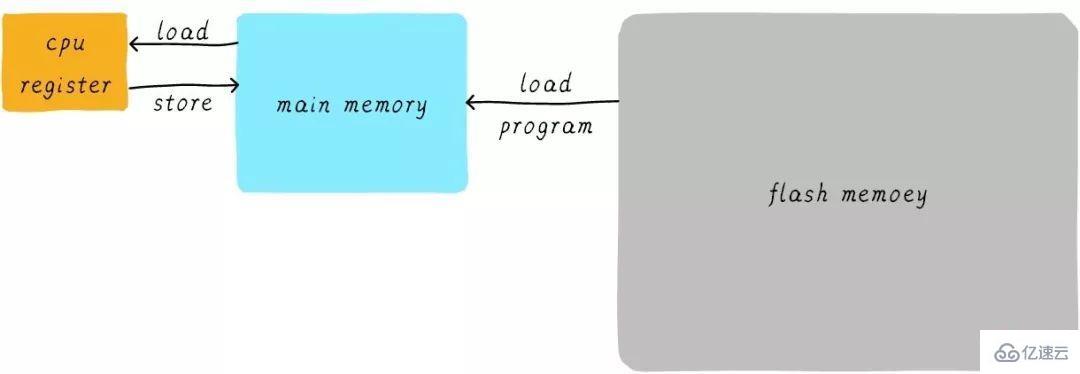
其實現實中,CPU通用寄存器的速度和主存之間存在著太大的差異。兩者之間的速度大致如下關系:

CPU register的速度一般小于1ns,主存的速度一般是65ns左右。速度差異近百倍。因此,上面舉例的3個步驟中,步驟1和步驟3實際上速度很慢。當CPU試圖從主存中load/store 操作時,由于主存的速度限制,CPU不得不等待這漫長的65ns時間。如果我們可以提升主存的速度,那么系統將會獲得很大的性能提升。
如今的DDR存儲設備,動不動就是幾個GB,容量很大。如果我們采用更快材料制作更快速度的主存,并且擁有幾乎差不多的容量。其成本將會大幅度上升。我們試圖提升主存的速度和容量,又期望其成本很低,這就有點難為人了。因此,我們有一種折中的方法,那就是制作一塊速度極快但是容量極小的存儲設備。那么其成本也不會太高。這塊存儲設備我們稱之為cache memory。
在硬件上,我們將cache放置在CPU和主存之間,作為主存數據的緩存。當CPU試圖從主存中load/store數據的時候, CPU會首先從cache中查找對應地址的數據是否緩存在cache 中。如果其數據緩存在cache中,直接從cache中拿到數據并返回給CPU。當存在cache的時候,以上程序如何運行的例子的流程將會變成如下:
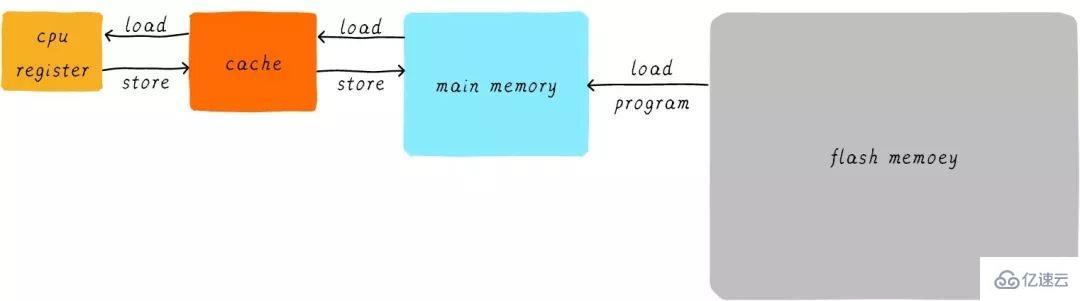
CPU和主存之間直接數據傳輸的方式轉變成CPU和cache之間直接數據傳輸。cache負責和主存之間數據傳輸。
cahe的速度在一定程度上同樣影響著系統的性能。
一般情況cache的速度可以達到1ns,幾乎可以和CPU寄存器速度媲美。但是,這就滿足人們對性能的追求了嗎?并沒有。當cache中沒有緩存我們想要的數據的時候,依然需要漫長的等待從主存中load數據。為了進一步提升性能,引入多級cache。
前面提到的cache,稱之為L1 cache(第一級cache)。我們在L1 cache 后面連接L2 cache,在L2 cache 和主存之間連接L3 cache。等級越高,速度越慢,容量越大。但是速度相比較主存而言,依然很快。不同等級cache速度之間關系如下:
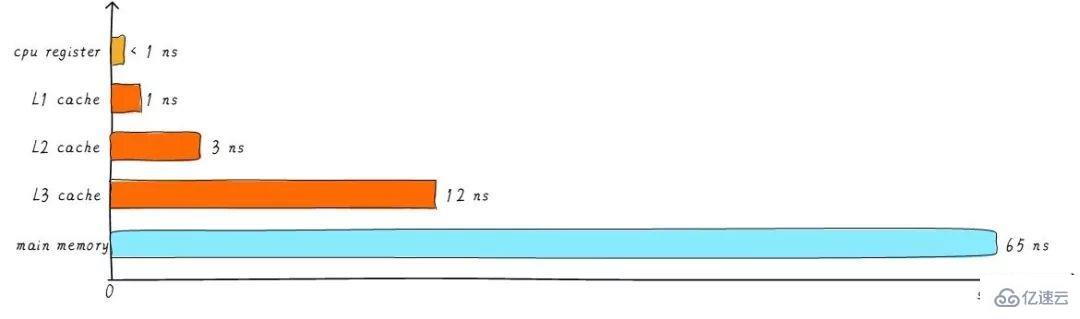
經過3級cache的緩沖,各級cache和主存之間的速度最萌差也逐級減小。在一個真實的系統上,各級cache之間硬件上是如何關聯的呢?我們看下Cortex-A53架構上各級cache之間的硬件抽象框圖如下:
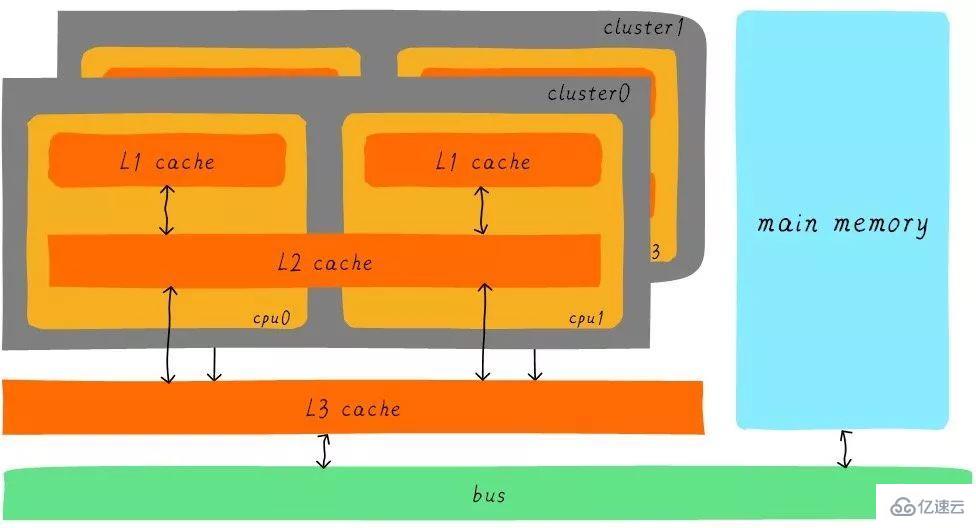
在Cortex-A53架構上,L1 cache分為單獨的instruction cache(ICache)和data cache(DCache)。L1 cache是CPU私有的,每個CPU都有一個L1 cache。一個cluster 內的所有CPU共享一個L2 cache,L2 cache不區分指令和數據,都可以緩存。所有cluster之間共享L3 cache。L3 cache通過總線和主存相連。
首先引入兩個名詞概念,命中和缺失。CPU要訪問的數據在cache中有緩存,稱為“命中” (hit),反之則稱為“缺失” (miss)。多級cache之間是如何配合工作的呢?我們假設現在考慮的系統只有兩級cache。
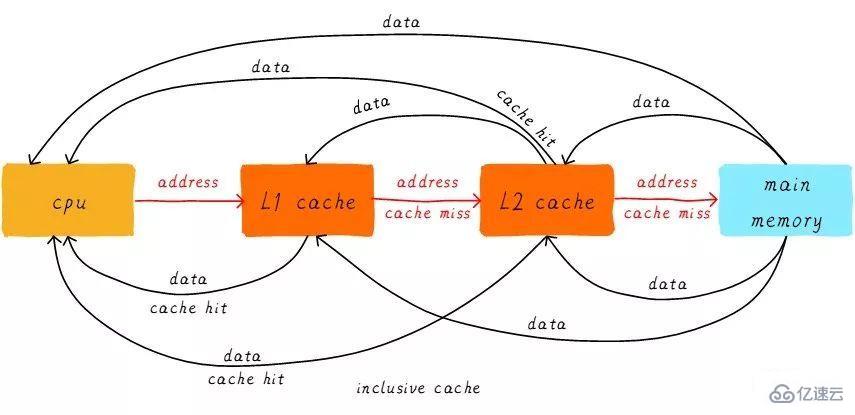
當CPU試圖從某地址load數據時,首先從L1 cache中查詢是否命中,如果命中則把數據返回給CPU。如果L1 cache缺失,則繼續從L2 cache中查找。當L2 cache命中時,數據會返回給L1 cache以及CPU。如果L2 cache也缺失,很不幸,我們需要從主存中load數據,將數據返回給L2 cache、L1 cache及CPU。這種多級cache的工作方式稱之為inclusive cache。
某一地址的數據可能存在多級緩存中。與inclusive cache對應的是exclusive cache,這種cache保證某一地址的數據緩存只會存在于多級cache其中一級。也就是說,任意地址的數據不可能同時在L1和L2 cache中緩存。
我們繼續引入一些cache相關的名詞。cache的大小稱之為cahe size,代表cache可以緩存最大數據的大小。我們將cache平均分成相等的很多塊,每一個塊大小稱之為cache line,其大小是cache line size。
例如一個64 Bytes大小的cache。如果我們將64 Bytes平均分成64塊,那么cache line就是1字節,總共64行cache line。如果我們將64 Bytes平均分成8塊,那么cache line就是8字節,總共8行cache line。現在的硬件設計中,一般cache line的大小是4-128 Byts。為什么沒有1 byte呢?原因我們后面討論。
這里有一點需要注意,cache line是cache和主存之間數據傳輸的最小單位。什么意思呢?當CPU試圖load一個字節數據的時候,如果cache缺失,那么cache控制器會從主存中一次性的load cache line大小的數據到cache中。例如,cache line大小是8字節。CPU即使讀取一個byte,在cache缺失后,cache會從主存中load 8字節填充整個cache line。又是因為什么呢?后面說完就懂了。
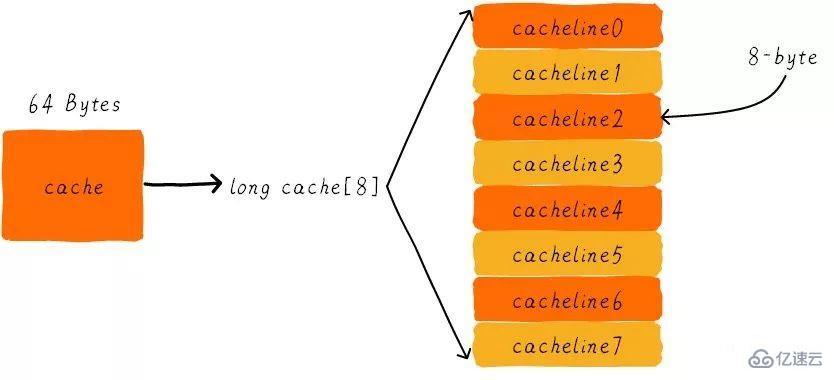
我們假設下面的講解都是針對64 Bytes大小的cache,并且cache line大小是8字節。我們可以類似把這塊cache想想成一個數組,數組總共8個元素,每個元素大小是8字節。就像下圖這樣。
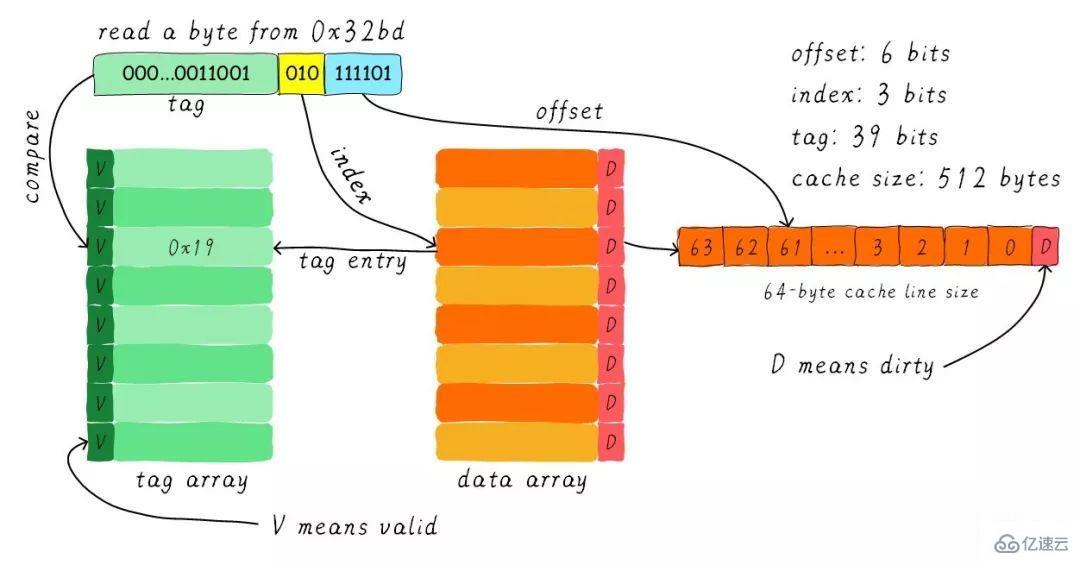
現在我們考慮一個問題,CPU從0x0654地址讀取一個字節,cache控制器是如何判斷數據是否在cache中命中呢?cache大小相對于主存來說,可謂是小巫見大巫。所以cache肯定是只能緩存主存中極小一部分數據。我們如何根據地址在有限大小的cache中查找數據呢?現在硬件采取的做法是對地址進行散列(可以理解成地址取模操作)。我們接下來看看是如何做到的?

我們一共有8行cache line,cache line大小是8 Bytes。所以我們可以利用地址低3 bits(如上圖地址藍色部分)用來尋址8 bytes中某一字節,我們稱這部分bit組合為offset。同理,8行cache line,為了覆蓋所有行。
我們需要3 bits(如上圖地址黃色部分)查找某一行,這部分地址部分稱之為index。現在我們知道,如果兩個不同的地址,其地址的bit3-bit5如果完全一樣的話,那么這兩個地址經過硬件散列之后都會找到同一個cache line。所以,當我們找到cache line之后,只代表我們訪問的地址對應的數據可能存在這個cache line中,但是也有可能是其他地址對應的數據。所以,我們又引入tag array區域,tag array和data array一一對應。
每一個cache line都對應唯一一個tag,tag中保存的是整個地址位寬去除index和offset使用的bit剩余部分(如上圖地址綠色部分)。tag、index和offset三者組合就可以唯一確定一個地址了。因此,當我們根據地址中index位找到cache line后,取出當前cache line對應的tag,然后和地址中的tag進行比較,如果相等,這說明cache命中。如果不相等,說明當前cache line存儲的是其他地址的數據,這就是cache缺失。
在上述圖中,我們看到tag的值是0x19,和地址中的tag部分相等,因此在本次訪問會命中。由于tag的引入,因此解答了我們之前的一個疑問“為什么硬件cache line不做成一個字節?”。這樣會導致硬件成本的上升,因為原本8個字節對應一個tag,現在需要8個tag,占用了很多內存。
我們可以從圖中看到tag旁邊還有一個valid bit,這個bit用來表示cache line中數據是否有效(例如:1代表有效;0代表無效)。當系統剛啟動時,cache中的數據都應該是無效的,因為還沒有緩存任何數據。cache控制器可以根據valid bit確認當前cache line數據是否有效。所以,上述比較tag確認cache line是否命中之前還會檢查valid bit是否有效。只有在有效的情況下,比較tag才有意義。如果無效,直接判定cache缺失。
上面的例子中,cache size是64 Bytes并且cache line size是8 bytes。offset、index和tag分別使用3 bits、3 bits和42 bits(假設地址寬度是48 bits)。我們現在再看一個例子:512 Bytes cache size,64 Bytes cache line size。根據之前的地址劃分方法,offset、index和tag分別使用6 bits、3 bits和39 bits。如下圖所示。
直接映射緩存在硬件設計上會更加簡單,因此成本上也會較低。根據直接映射緩存的工作方式,我們可以畫出主存地址0x00-0x88地址對應的cache分布圖。
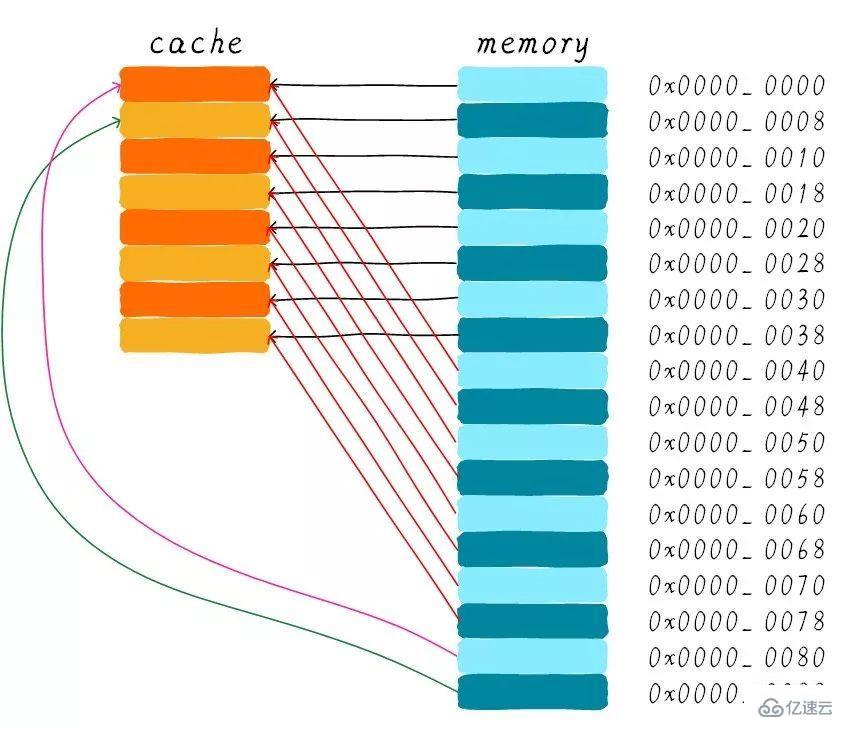
我們可以看到,地址0x00-0x3f地址處對應的數據可以覆蓋整個cache。0x40-0x7f地址的數據也同樣是覆蓋整個cache。我們現在思考一個問題,如果一個程序試圖依次訪問地址0x00、0x40、0x80,cache中的數據會發生什么呢?
首先我們應該明白0x00、0x40、0x80地址中index部分是一樣的。因此,這3個地址對應的cache line是同一個。所以,當我們訪問0x00地址時,cache會缺失,然后數據會從主存中加載到cache中第0行cache line。當我們訪問0x40地址時,依然索引到cache中第0行cache line,由于此時cache line中存儲的是地址0x00地址對應的數據,所以此時依然會cache缺失。然后從主存中加載0x40地址數據到第一行cache line中。同理,繼續訪問0x80地址,依然會cache缺失。
這就相當于每次訪問數據都要從主存中讀取,所以cache的存在并沒有對性能有什么提升。訪問0x40地址時,就會把0x00地址緩存的數據替換。這種現象叫做cache顛簸(cache thrashing)。針對這個問題,我們引入多路組相連緩存。我們首先研究下最簡單的兩路組相連緩存的工作原理。
我們依然假設64 Bytes cache size,cache line size是8 Bytes。什么是路(way)的概念。我們將cache平均分成多份,每一份就是一路。因此,兩路組相連緩存就是將cache平均分成2份,每份32 Bytes。如下圖所示。
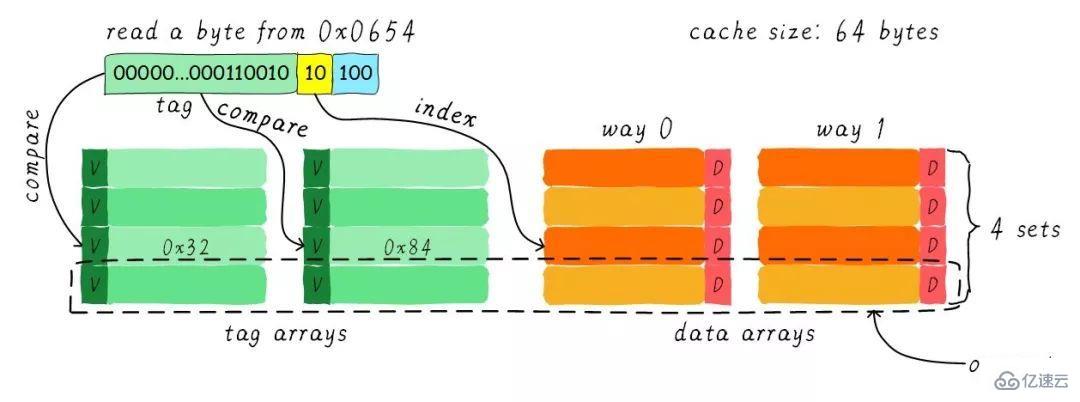
cache被分成2路,每路包含4行cache line。我們將所有索引一樣的cache line組合在一起稱之為組。例如,上圖中一個組有兩個cache line,總共4個組。我們依然假設從地址0x0654地址讀取一個字節數據。由于cache line size是8 Bytes,因此offset需要3 bits,這和之前直接映射緩存一樣。不一樣的地方是index,在兩路組相連緩存中,index只需要2 bits,因為一路只有4行cache line。
上面的例子根據index找到第2行cache line(從0開始計算),第2行對應2個cache line,分別對應way 0和way 1。因此index也可以稱作set index(組索引)。先根據index找到set,然后將組內的所有cache line對應的tag取出來和地址中的tag部分對比,如果其中一個相等就意味著命中。
因此,兩路組相連緩存較直接映射緩存最大的差異就是:第一個地址對應的數據可以對應2個cache line,而直接映射緩存一個地址只對應一個cache line。那么這究竟有什么好處呢?
兩路組相連緩存的硬件成本相對于直接映射緩存更高。因為其每次比較tag的時候需要比較多個cache line對應的tag(某些硬件可能還會做并行比較,增加比較速度,這就增加了硬件設計復雜度)。
為什么我們還需要兩路組相連緩存呢?因為其可以有助于降低cache顛簸可能性。那么是如何降低的呢?根據兩路組相連緩存的工作方式,我們可以畫出主存地址0x00-0x4f地址對應的cache分布圖。
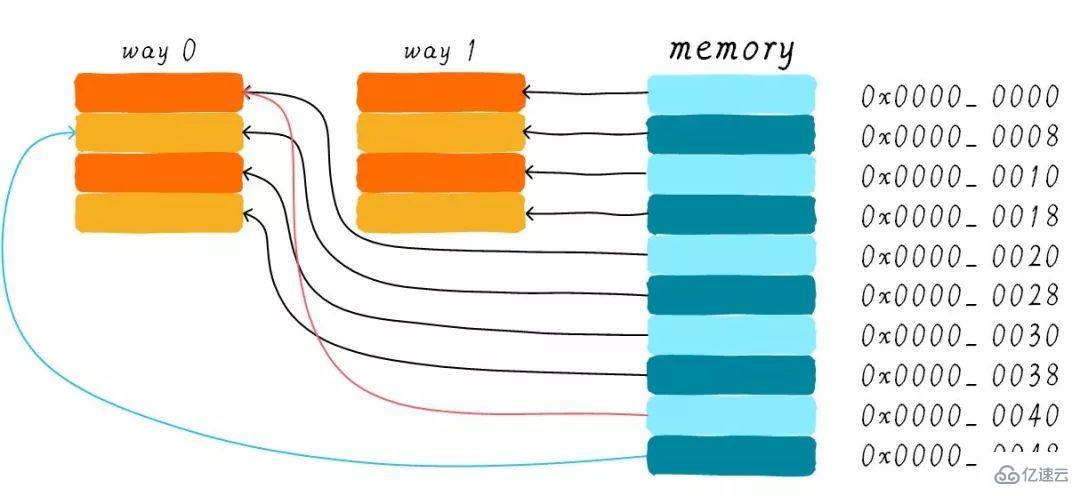
我們依然考慮直接映射緩存一節的問題“如果一個程序試圖依次訪問地址0x00、0x40、0x80,cache中的數據會發生什么呢?”。現在0x00地址的數據可以被加載到way 1,0x40可以被加載到way 0。這樣是不是就在一定程度上避免了直接映射緩存的尷尬境地呢?在兩路組相連緩存的情況下,0x00和0x40地址的數據都緩存在cache中。試想一下,如果我們是4路組相連緩存,后面繼續訪問0x80,也可能被被緩存。
因此,當cache size一定的情況下,組相連緩存對性能的提升最差情況下也和直接映射緩存一樣,在大部分情況下組相連緩存效果比直接映射緩存好。同時,其降低了cache顛簸的頻率。從某種程度上來說,直接映射緩存是組相連緩存的一種特殊情況,每個組只有一個cache line而已。因此,直接映射緩存也可以稱作單路組相連緩存。
既然組相連緩存那么好,如果所有的cache line都在一個組內。豈不是性能更好。是的,這種緩存就是全相連緩存。我們依然以64 Byts大小cache為例說明。
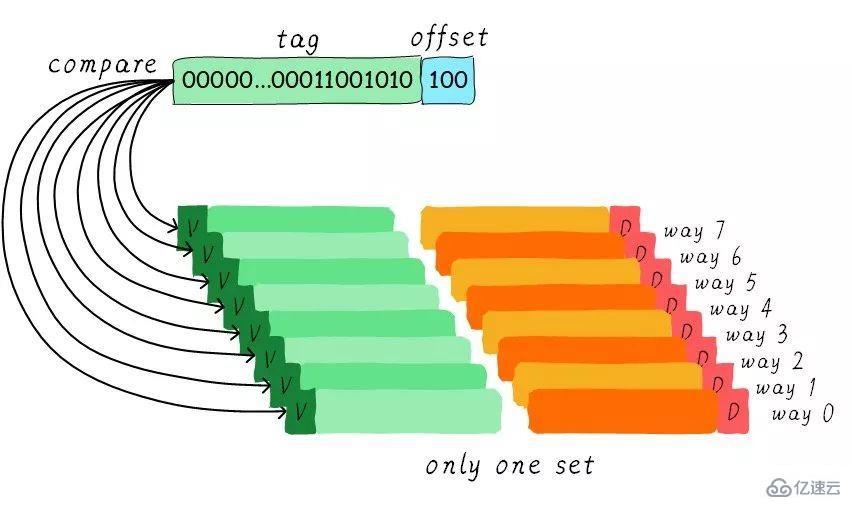
由于所有的cache line都在一個組內,因此地址中不需要set index部分。因為,只有一個組讓你選擇,間接來說就是你沒得選。我們根據地址中的tag部分和所有的cache line對應的tag進行比較(硬件上可能并行比較也可能串行比較)。哪個tag比較相等,就意味著命中某個cache line。因此,在全相連緩存中,任意地址的數據可以緩存在任意的cache line中。所以,這可以最大程度的降低cache顛簸的頻率。但是硬件成本上也是更高。
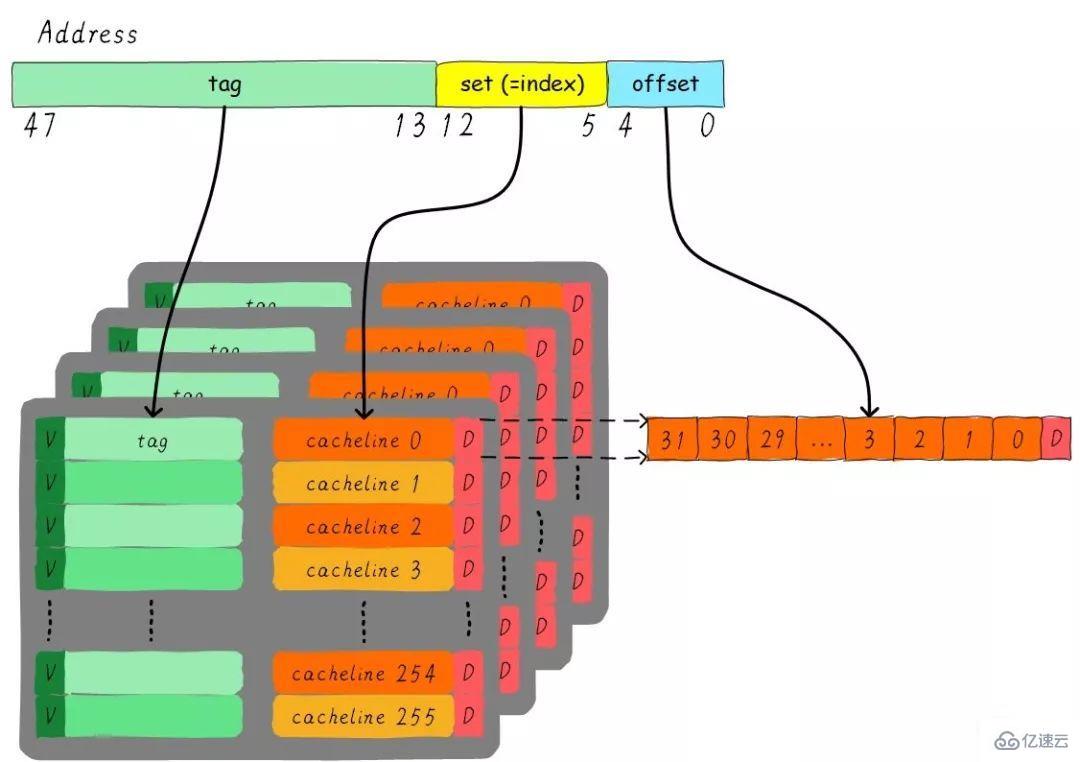
考慮這么一個問題,32 KB大小4路組相連cache,cache line大小是32 Bytes。請思考一下問題:
1). 多少個組?2). 假設地址寬度是48 bits,index、offset以及tag分別占用幾個bit?
總共4路,因此每路大小是8 KB。cache line size是32 Bytes,因此一共有256組(8 KB / 32 Bytes)。由于cache line size是32 Bytes,所以offset需要5位。一共256組,所以index需要8位,剩下的就是tag部分,占用35位。這個cache可以繪制下圖表示。
cache的分配策略是指我們什么情況下應該為數據分配cache line。cache分配策略分為讀和寫兩種情況。
讀分配(read allocation):
當CPU讀數據時,發生cache缺失,這種情況下都會分配一個cache line緩存從主存讀取的數據。默認情況下,cache都支持讀分配。
寫分配(write allocation):
當CPU寫數據發生cache缺失時,才會考慮寫分配策略。當我們不支持寫分配的情況下,寫指令只會更新主存數據,然后就結束了。當支持寫分配的時候,我們首先從主存中加載數據到cache line中(相當于先做個讀分配動作),然后會更新cache line中的數據。
cache更新策略是指當發生cache命中時,寫操作應該如何更新數據。cache更新策略分成兩種:寫直通和回寫。
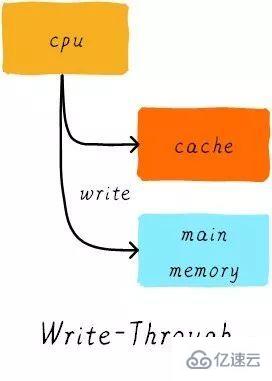
寫直通(write through):
當CPU執行store指令并在cache命中時,我們更新cache中的數據并且更新主存中的數據。cache和主存的數據始終保持一致。
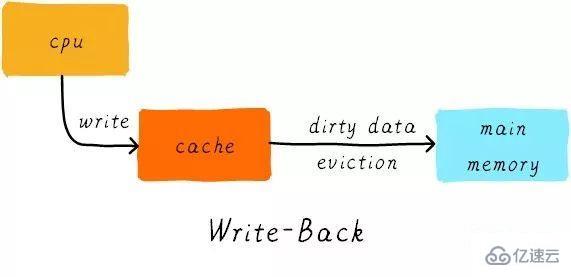
寫回(write back):
當CPU執行store指令并在cache命中時,我們只更新cache中的數據。并且每個cache line中會有一個bit位記錄數據是否被修改過,稱之為dirty bit(翻翻前面的圖片,cache line旁邊有一個D就是dirty bit)。我們會將dirty bit置位。主存中的數據只會在cache line被替換或者顯示clean操作時更新。因此,主存中的數據可能是未修改的數據,而修改的數據躺在cache line中。
同時,為什么cache line大小是cache控制器和主存之間數據傳輸的最小單位呢?這也是因為每個cache line只有一個dirty bit。這一個dirty bit代表著整個cache line時候被修改的狀態。
假設我們有一個64 Bytes大小直接映射緩存,cache line大小是8 Bytes,采用寫分配和寫回機制。當CPU從地址0x2a讀取一個字節,cache中的數據將會如何變化呢?假設當前cache狀態如下圖所示。
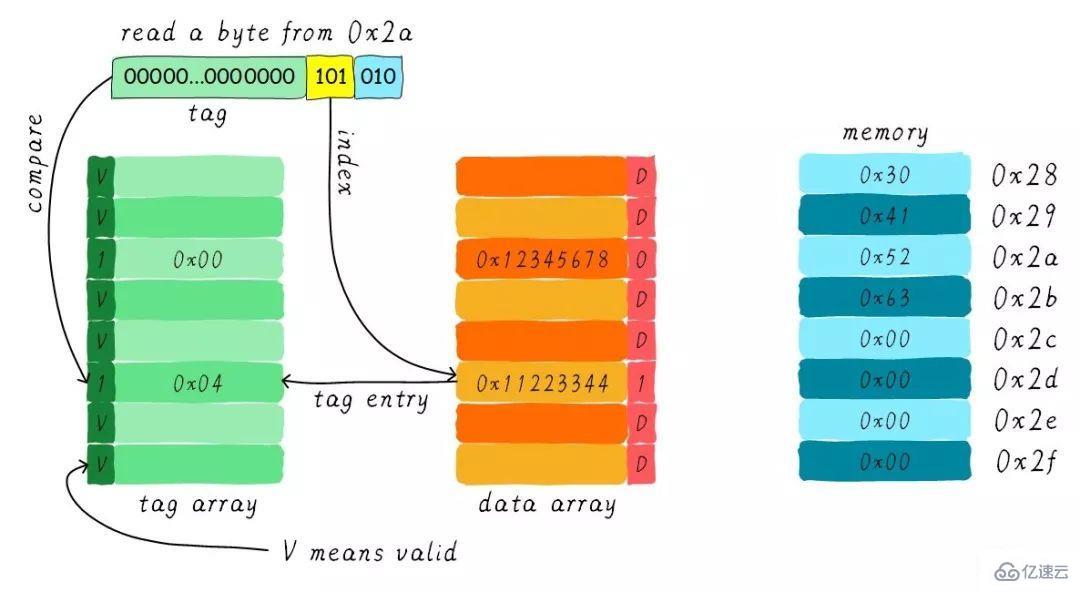
根據index找到對應的cache line,對應的tag部分valid bit是合法的,但是tag的值不相等,因此發生缺失。此時我們需要從地址0x28地址加載8字節數據到該cache line中。但是,我們發現當前cache line的dirty bit置位。因此,cache line里面的數據不能被簡單的丟棄,由于采用寫回機制,所以我們需要將cache中的數據0x11223344寫到地址0x0128地址(這個地址根據tag中的值及所處的cache line行計算得到)。這個過程如下圖所示。
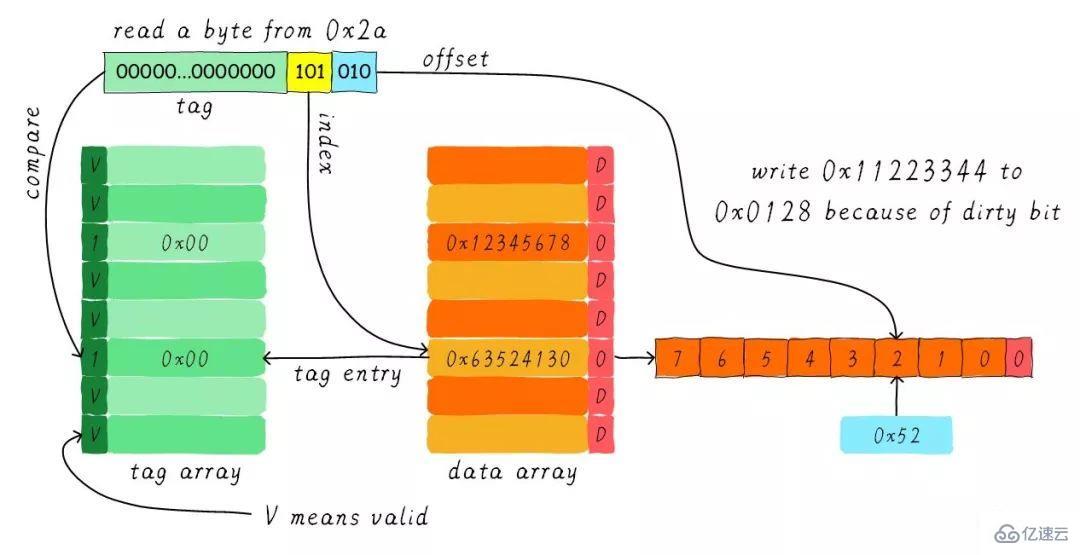
當寫回操作完成,我們將主存中0x28地址開始的8個字節加載到該cache line中,并清除dirty bit。然后根據offset找到0x52返回給CPU。
關于Linux中的Cache Memory就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





