溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
正文
與事務處理應用相比,大數據服務屬于分析處理應用,由于兩者的數據處理特點不同,因此容量估算方法也有一定的區別。
大數據服務通常要經過數據ETL、數據存儲、數據分析、數據展示、數據開放的過程,因此在計算能力、存儲能力以及網絡能力的估算上也有自身的特點。
大數據服務在不同階段對于基礎設施的需求如圖3-2-19所示:
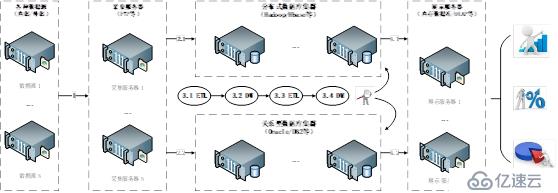
圖3-2-19大數據服務不同階段基礎設施需求
從圖3-2-19可以看出,對于一個普通的大數據項目,通常要經過數據采集(1)、數據存儲和數據轉換(2.1,2.2,3.1,3.2,3.3,3.4)、數據展示(4.1,4.2)三大步驟,具體處理過程為:
數據源分為內部和外部數據源兩種。內部數據源是企業自身的數據,比如電信運營商的用戶上網數據是從交換機獲取的業務使用記錄;
外部數據源是企業從外部獲取的數據,比如移動終端配置數據是從第三方公司數據庫獲取的。采集數據的方式也分為主動和被動兩種。
主動方式是主動去數據源抓取數據,比如可以通過網絡爬蟲在各大網站獲取數據;被動方式是企業為數據源設定好存儲位置,讓數據提供方按照時間策略向指定位置存放數據。
企業可以根據數據特點不同采取不同的數據存儲策略,如果數據規模大或者預期的數據規模大,傳統的關系型數據庫無法滿足快速處理要求的,因而需要考慮采用分布式數據庫,比如Hadoop/HBase。
類似Hadoop/HBase這樣的分布式數據庫的特點是擴展性好,如果存儲空間不夠,只需增加存儲服務器即可。不足之處是HBase只適合單表或者多表之間關聯關系簡單的場景,對于需要數據操作或者多表關聯的應用,還是需要基于關系型數據庫實現。
關系型數據的優勢就是能夠對數據進行整合和統計,從而使得用戶可以從多個維度來查看分析結果。當然,由于關系型數據庫基于單機模式完成的架構設計,盡管也可以支持集群方式部署,但是橫向擴展能力有限。
可見,多表關聯查詢要比鍵值映射方式對數據庫管理系統的要求高,但是沒有鍵值映射的方式擴展性好。
因此,在大數據存儲時,需要結合應用需求和數據庫存儲特征來進行綜合考量:使用分布式數據來存儲數據規模大、增量大并且以數據查詢為主的數據,采用關系型數據庫完成需要多表關聯的查詢統計功能。
當原始數據存儲到數據庫中以后,需要對數據進行抽取、轉換與加載,保證數據質量和應用要求。數據過程過程通常是經過初步的ETL,然后將數據存儲數據倉庫,接著再次對數據進行ETL,將數據加工成面向不同主題的數據集市,以便于從多個維度查看數據統計結果。
雖然已經經費了很大力氣完成了數據的抽取、轉換、豐富等工作,但是數據畢竟是給人看的,數據展示的越好,越容易讓用戶看到數據背后隱藏的事實和規律。
比如電信運營商為了查看各地區數據流量的多少,可以基于電子地圖,不同數據流量區間用不同顏色標識,這樣可以直觀地看到各省數據流量的多寡。
大數據分析處理系統容量估算可以分為:理論估算法和實驗估算法兩種類型。
理論估算法的數據基礎包括文件數、單個文件數的記錄條數、單條記錄大小、數據采集周期,數據采集周期包括一次、一天、一個月等,這樣就能夠算出某個時間段內的總數據量大小。然后在考慮磁盤的冗余空間系數,就可以算出對于磁盤空間總的需求量。理論估算法適合于沒有樣本數據的場景。
理論估算法的計算公式為:存儲空間大小 = 文件個數單個文件記錄數單條記錄大小時間長度冗余系數。
實驗估算法基于某個時間段的樣本數據。用戶可以用操作系統自帶的命令查看文件大小。如果進入數據倉庫的數據從時間上是連續的,則可以通過樣本數據測量值與時間長度相乘,算出大數據分析處理系統存儲空間需求。
實驗估算法的計算公式為:大數據分析處理系統存儲空間大小 = 樣本數據量大小時間長度冗余系數。
傳統數據處理與存儲架構是“主機+磁盤陣列”的集群方式,主機可以是小機、PC服務器或者刀片服務器,磁盤陣列可以是NAS、SAN等,采用的協議可以是FC、IP等。
傳統數據處理與存儲架構解決了存儲資源和計算資源的共享問題。多個服務器組成的集群可以將計算資源統一管理,接收請求的負載均衡器會根據服務器負荷將請求發送到計算資源充足的服務器。
磁盤陣列實現共享的方式更加容易理解,就是多個磁盤放到一個機箱中,機箱可以擴展并且機箱內可以熱插拔磁盤,這樣可以便于擴展磁盤空間。
“主機+磁盤陣列”的系統架構是將計算和存儲分離,通過計算群和存儲群的方式提高了并行處理能力,滿足了高并發的事務處理應用的系統要求,但是這種架構也帶來了新的問題,就是計算和存儲資源的橫向擴展能力是有限的。
大數據服務的特點是數據量大,尤其是隨著時間的推移,數據量會不斷增大,要求計算和存儲資源能夠具備幾乎沒有限制的擴展能力。
為了滿足不斷增加的數據量,谷歌公司提出了基于MapReduce和GFS的分布式計算架構,與“主機+磁盤陣列”的架構方式不同,谷歌公司利用廉價的機器設備,通過軟件將能力不一的大量計算機設備連接到一起,降低了IT基礎設施采購成本,提升了IT基礎設施的擴展能力。隨后,Apache受谷歌的GFS/MapReduce架構的啟發,提出了Hadoop分布式計算架構。
可見,新型的面向大數據的分布式計算架構與“主機+磁盤陣列”的系統架構在設計思路上完全不同的,大數據計算能力估算的方法也是不同的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





