溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本期開始,我們將陸續分享Tungsten Fabric用戶案例文章,一起發現TF的更多應用場景。“揭秘LOL”系列的主人公是TF用戶Riot Games游戲公司,作為LOL《英雄聯盟》的開發和運營商,Riot Games面臨全球范圍復雜部署的挑戰,讓我們一起揭秘LOL背后的“英雄們”,看他們是如何運行在線服務的吧。
作者:Jonathan McCaffrey(文章來源:Riot Games)
我叫Jonathan McCaffrey,在Riot的基礎架構團隊工作。這是該系列文章中的第一篇,我們將深入探討如何在全球范圍內部署和操作后端功能。在深入探討技術細節之前,重要的是要了解Rioters(Riot人)如何考慮功能開發。在Riot,玩家的價值至高無上,開發團隊通常直接與玩家社區合作,以提供功能和改進信息。為了提供最佳的玩家體驗,我們需要快速行動,并具備可以根據反饋保持快速更改計劃的能力。基礎架構團隊的任務,就是為我們的開發人員能做到這一點鋪平道路——越是加強Riot團隊的能力,就可以越快地將功能交付給玩家使用。
當然,說起來容易做起來難!鑒于我們在部署上的多樣性,因此出現了許多挑戰:我們的服務器遍布在公共云、私有數據中心,以及騰訊和Garena這樣的合作伙伴環境當中,所有這些環境在地理位置和技術上都各不相同。
當功能團隊準備好交付組件時,這種復雜性給他們帶來了巨大的負擔。那就是基礎架構團隊的職責所在——我們通過基于容器的內部云環境(我們稱為“rCluster”)消除了一些部署障礙。在本文中,我將討論Riot從手動部署到使用rCluster啟動功能的歷程。為了說明rCluster的產品和技術,我將逐步介紹Hextech Crafting系統的發布(Hextech Crafting是英雄聯盟的開箱系統的名字)。
7年前,當我剛開始在Riot工作時,我們并沒有太多的部署或服務器管理流程,Riot當時是一家具有遠見卓識,但預算少并且需要快速發展的初創公司。當為《英雄聯盟》構建生產環境基礎架構時,我們匆忙的滿足游戲的需求、從開發人員帶來的更多功能的需求,來自區域團隊的在全球開設新區的需求。我們手動啟用服務器和應用,很少考慮原則或戰略規劃。
在此過程中,我們轉向利用Chef完成許多常見的部署和基礎設施任務。同時,開始將越來越多的公共云用于大數據和Web工作。這些變革也多次觸發了我們的網絡設計、供應商選擇和團隊結構的變化。
我們的數據中心容納了數千臺服務器,并且幾乎為每個新應用程序都安裝了新的服務器。新服務器將存在于自己手動創建的VLAN中,并具備路由和防火墻規則,以實現網絡之間的安全訪問。盡管此過程可以幫助我們提高安全性并明確定義故障域,但它既費時又費力。更麻煩的是,當時的大多數新功能都被設計為小型Web服務,這使得我們的LoL(英雄聯盟)的生態系統,獨立應用的數量激增。
最重要的是,開發團隊對他們的應用程序測試能力缺乏信心,尤其是在涉及諸如配置和網絡連接之類的部署問題時。將應用程序與物理環境緊密聯系在一起,意味著生產數據中心環境之間的差異不會在QA(測試)、Staging(上線前)和PBE(基于模式開發)中復制。每個環境都是手工制作的、獨特的,到最后始終也不能一致。(注釋:本文主要想描述的兩個問題,第一是客戶的應用和環境緊密相關,但是由于不同的團隊或者部門的應用環境不同,因此可能出現因為不一致對應用上線帶來問題)
當我們在應用程序數量不斷增加的生態系統中,應對手動服務器和網絡配置的挑戰時,Docker開始在我們的開發團隊中獲得普及,作為解決配置一致性和開發環境問題的方法。一旦開始使用,我們能明顯感覺到Docker可以做更多的事情,并且可以在處理基礎架構的過程中發揮關鍵作用。
當時基礎架構團隊設定了一個目標,為2016賽季的玩家,開發人員和Riot公司解決這些問題。到2015年底,我們已經從手動部署功能,轉變為以自動化且一致的方式在Riot地區部署類似Hextech Crafting等功能。我們的解決方案是用rCluster這一全新的系統,該系統在微服務架構中利用了Docker和SDN軟件定義網絡。切換到rCluster可以彌補我們在環境和部署過程中的不一致之處,并使產品團隊可以專注于他們的產品開發。
讓我們深入研究一下這項技術,以了解rCluster如何在后臺支持Hextech Crafting等功能。解釋一下,Hextech Crafting是《英雄聯盟》的一項功能,可為玩家提供一種解鎖游戲內物品的新方法。
該功能內部稱為“Loot”,由3個核心組件組成:
當你打開crafting屏幕時,將發生以下情況:
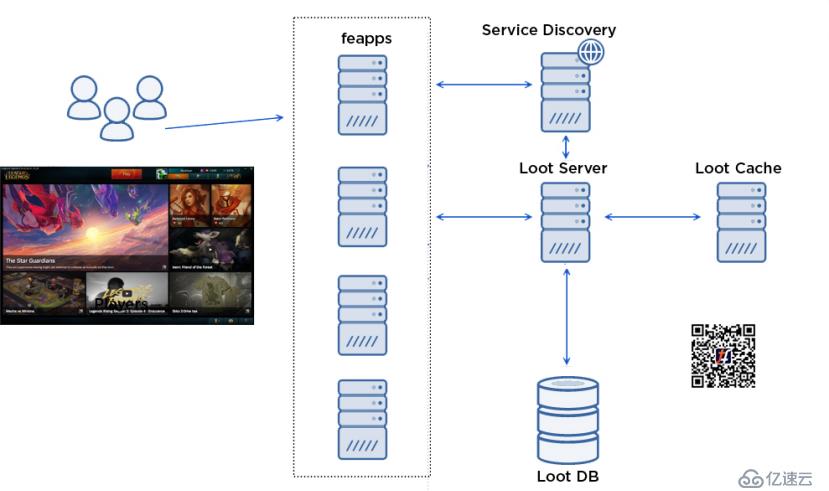
玩家在客戶端中打開crafting屏幕。
客戶端對前端應用程序(也稱為“feapp”)進行RPC調用,以代理玩家和內部后端服務之間的調用。
與Loot團隊合作,我們能夠將Server和Cache層內置到Docker容器中,并且它們的部署配置在JSON文件中定義,如下所示:
Loot服務器JSON示例: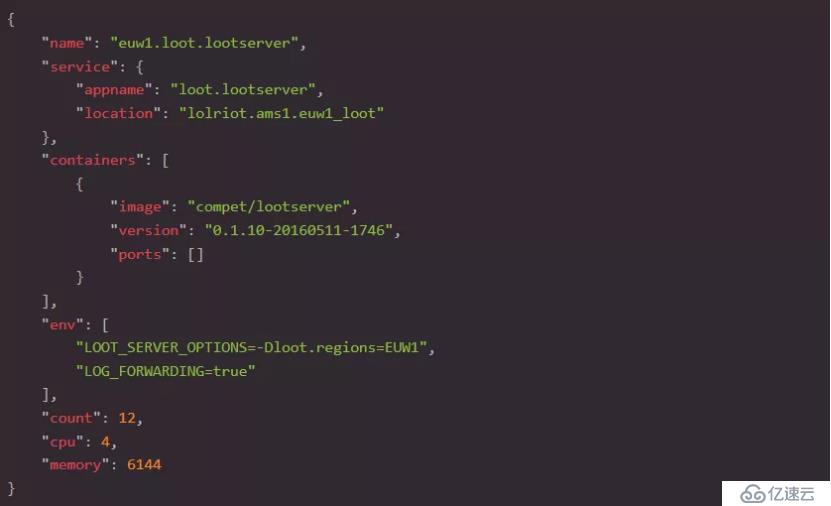
Loot緩存JSON示例: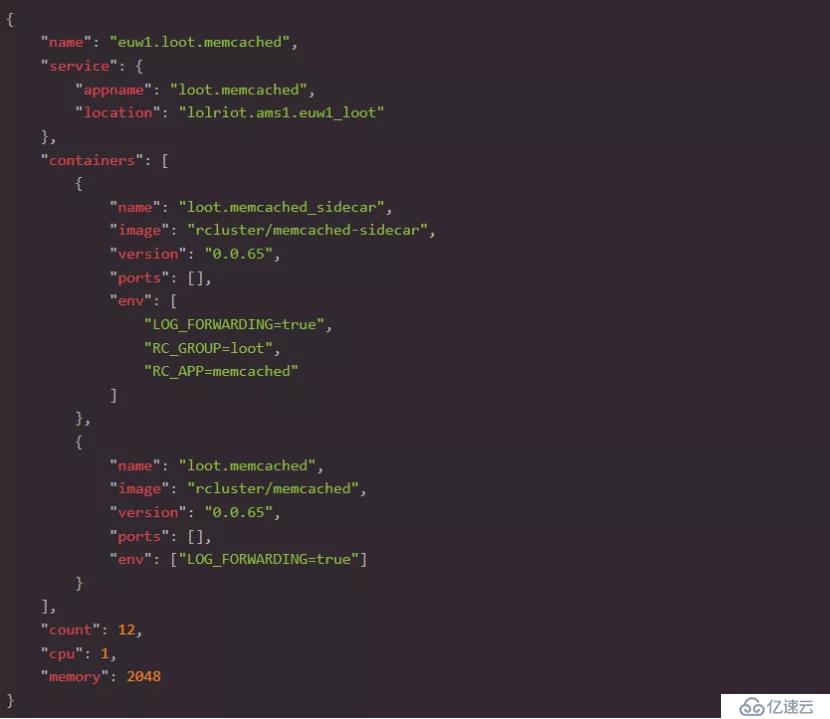
但是,要實際部署此功能,并在減少前述的問題方面取得真正的進展——我們需要在北美、南美、歐洲和亞洲等地創建可以支持Docker的集群。這需要我們解決一堆難題,例如:
隨后的文章將更詳細地介紹rCluster系統的這些組件,在這里我簡要概述一下每個組件。
我們使用編寫的Admiral軟件在rCluster生態系統中實現了容器調度。Admiral跨過一系列物理機器與Docker守護進程(daemons)進行對話,以了解其當前的運行狀態。用戶通過HTTPS發送上述JSON(Admiral用來更新了解對相關容器所需的狀態)來發出請求,然后,它會連續掃描集群的活動狀態和所需狀態,以找出需要采取的措施。最后,Admiral再次調用Docker守護程序來啟動和停止容器,以收斂于所需的狀態。
如果某個容器崩潰,Admiral可以發現實時狀態與期望狀態間的差異,并在另一臺主機上啟動該容器以對其進行糾正。這種靈活性使管理服務器變得更加容易,因為我們可以無縫地“榨干”它們,加以維護,或者重新啟用它們以處理工作負載。
Admiral與開源工具Marathon相似,因此我們正在研究移植工作以利用Mesos、Marathon和DC/OS。如果這項工作取得成果,我們將在以后的文章中討論。
容器運行后,我們需要在Loot應用程序和生態系統的其他部分之間提供網絡連接。為此,我們利用OpenContrail為每個應用程序提供了專用網絡,并讓我們的開發團隊使用GitHub中的JSON文件自己管理其策略。
Loot服務器網絡:
Loot緩存網絡: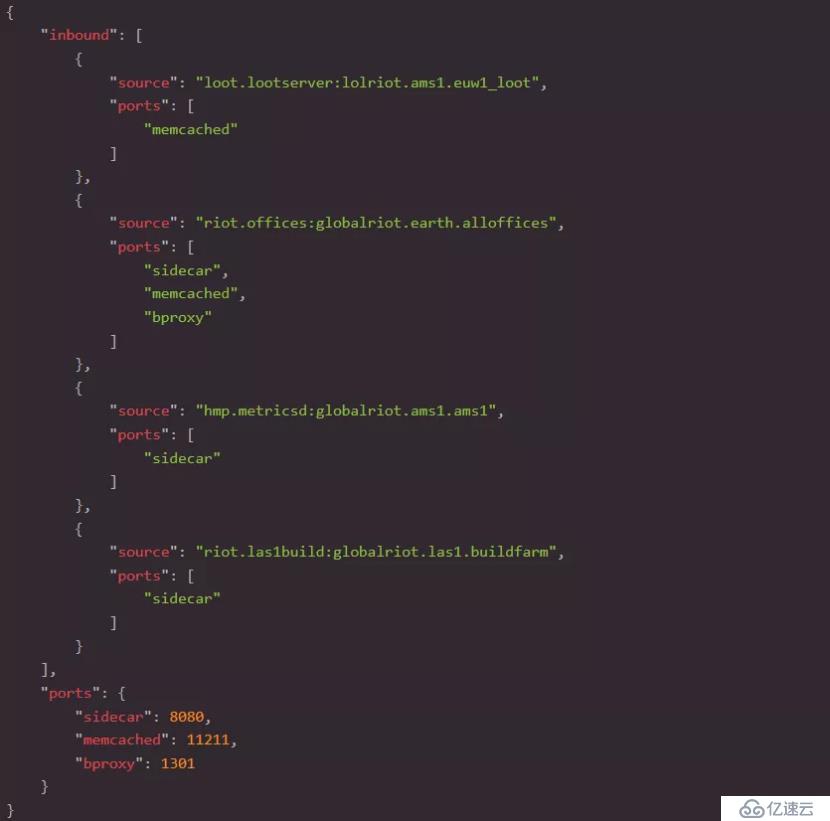
當工程師在GitHub中更改此配置時,將運行一個轉換作業,并在Contrail中進行API調用,為其應用程序的專用網絡創建和更新策略。
Contrail使用一種稱為“Overlay Networking”的技術來實現這些專用網絡。在我們的案例中,Contrail 在計算主機之間使用GRE隧道,并使用網關路由器來管理進入和離開overlay隧道并前往網絡其余部分的流量。OpenContrail系統的靈感來自于標準MPLS L3V P N,并且在概念上與標準MPLS L3V P N非常相似。可以在這里找到更深入的架構細節。(附注:opencontrail現在已經改名為TF)
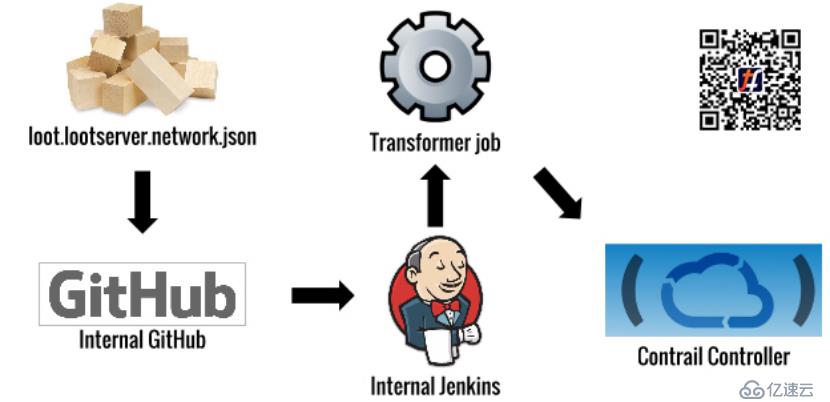
在實施此系統時,我們必須解決一些關鍵挑戰:
對于Loot應用程序,CI流程如下所示:
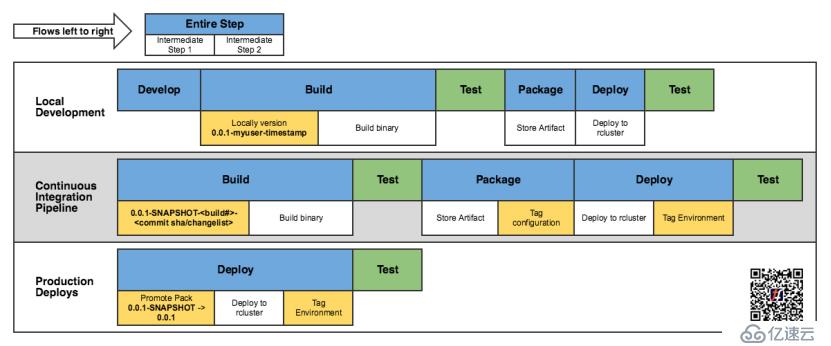
此處的總體目標是,當更改主倉庫(Master repo)時,將創建一個新的應用程序容器并將其部署到QA環境。有了這個工作流程,團隊可以快速迭代他們的代碼,并查看實際游戲中反映的更改。緊密的反饋回路,使得迅速改善體驗成為可能,這是Riot“專注于玩家”工程的主要目標。
至此,我們已經討論了如何構建和部署Hextech Crafting之類的功能,但是,如果你花了很多時間在這樣的容器環境上工作,那便不是問題所在。
在rCluster模型中,容器具有動態IP地址,并且不斷跳轉。這與我們以前的靜態服務器和部署方法完全不同,因此需要有效的新工具和流程。
其中一些關鍵問題如下:
為了解決這些問題,我們必須構建一個微服務平臺,來處理諸如服務發現、配置管理和監視之類的事情。在本系列的最后一部分中,我們將深入探討該系統及其解決問題的更多細節。
希望本文能為你提供一個概覽,了解我們正在嘗試解決的各種問題,以使Riot更加輕松地傳遞玩家價值。如前所述,我們將在后續文章中重點介紹rCluster對調度的使用、與Docker進行聯網,以及運行動態應用程序。
如果你正處于類似的“旅程”中,或者想參與討論,非常歡迎與我們取得聯系。

關注微信:TF中文社區
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





