溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Apache Commons Configuration讀取xml配置的方法,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
近期項目自己手寫一個字符串連接池。因為環境不同有開發版本、測試版本、上線版本、每一個版本用到的數據庫也是不一樣的。所以需要能靈活的切換數據庫連接。當然這個用maven就解決了。Apache Commons Configuration 框架用的主要是解析數據庫連接字符串。
下面介紹Apache Commons Configuration 框架的常用部分。
**
下載jar包http://www.php.cn/或者http://www.php.cn/ maven中搜索下載
研究api的使用。
·當xml結構大變化的時候不用過多的修改解析xml的代碼
用戶只需要修改自己的解析語法樹即可。
客戶只需要修改語法樹框架去解析,思考的起點是不是跟設計模式中的解釋器模式類似。構建抽象語法樹并解釋執行。
用戶只需要關心和修改自己的解析語法樹即可。
用戶不用關系如何解析只需要配置對應的解析語法規則即可。
簡化程序xml配置結構變化后大幅度的修改代碼。
首先先配置一下Maven。
<dependency>
<groupId>commons-configuration</groupId>
<artifactId>commons-configuration</artifactId>
<version>1.8</version>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>commons-jxpath</groupId>
<artifactId>commons-jxpath</artifactId>
<version>1.3</version>
</dependency>定義一個springok1.xml內容如下 
<?xml version="1.0" encoding="UTF-8"?><!-- springok1.xml --><config>
<database>
<url>127.0.0.1</url>
<port>3306</port>
<login>admin</login>
<password></password>
</database></config>public static void main(String[] args) throws Exception {
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
System.out.println(conf.getString("database.url"));
System.out.println(conf.getString("database.port"));
System.out.println(conf.getString("database.login"));
System.out.println(conf.getString("database.password"));
}輸出如下:說明已經成功解析xml了。
127.0.0.1
3306
admin
獲取的方法有很多種更詳細的獲取方法可以從AbstractConfiguration方法中對應找到。
上面配置的是一個數據庫的連接信息,如果配置很多數據庫的連接信息,怎么解析連接信息切換呢。修改springok1.xml的信息為多個連接配置如下:
<?xml version="1.0" encoding="UTF-8"?><!-- springok1.xml --><config><databases>
<database>
<url>127.0.0.1</url>
<port>3306</port>
<login>admin</login>
<password></password>
</database>
<database>
<url>127.0.0.1</url>
<port>3302</port>
<login>admin</login>
<password>admin</password>
</database></databases></config>現在假設我們要獲取兩個的配置數據庫連接信息,程序如下:
public static void main(String[] args) throws Exception {
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
System.out.println(conf.getString("databases.database(0).url"));
System.out.println(conf.getString("databases.database(0).port"));
System.out.println(conf.getString("databases.database(0).login"));
System.out.println(conf.getString("databases.database(0).password"));
System.out.println(conf.getString("databases.database(1).url"));
System.out.println(conf.getString("databases.database(1).port"));
System.out.println(conf.getString("databases.database(1).login"));
System.out.println(conf.getString("databases.database(1).password"));
}輸出:
127.0.0.1
3306
admin
127.0.0.1
3302
admin
admin
解析ok,
結合前面的配置文件的例子跟實戰我們發現多個相同的標簽的話索引是從0開始的。
點的訪問方式上面的那種方式是沒問題,對于一些復雜的配置來講,我們可能需要使用XPath表達式語言。這里的主要優點是,使用了XML的高級查詢,程序看起來仍然比較簡潔易懂。可理解性高。 
還是解析上面的springok.xml文件。代碼如下:
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
conf.setExpressionEngine(new XPathExpressionEngine());
System.out.println(conf.getString("databases/database[port='3306']/url"));
System.out.println(conf.getString("databases/database[port='3302']/port"));輸出:
127.0.0.1
3302
測試ok.
EnvironmentConfiguration conf=new EnvironmentConfiguration();
System.out.println(conf.getMap());源碼分析如何實現:
public EnvironmentConfiguration()
{ super(new HashMap<String, Object>(System.getenv()));
}聯合一和2兩種方式,是不是我們可以再系統變量中定義一個需要連接的數據庫字符串key,解析的時候獲取動態加載呢?
public String getDbUrl() throws ConfigurationException {
EnvironmentConfiguration envConfig =new EnvironmentConfiguration(); String env = envConfig.getString("ENV_TYPE"); if("dev".equals(env) ||"production".equals(env)) {
XMLConfiguration xmlConfig =new XMLConfiguration("springok1.xml");
xmlConfig.setExpressionEngine(new XPathExpressionEngine()); String xpath ="databases/database[name = '"+ env +"']/url"; return xmlConfig.getString(xpath);
}else{ String msg ="ENV_TYPE environment variable is "+
"not properly set";
throw new IllegalStateException(msg);
}
}測試ok沒問題。
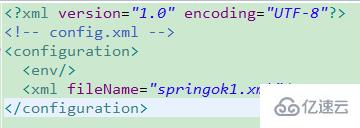
xml配置如下圖:
public String getDbUrl()throws ConfigurationException {
DefaultConfigurationBuilder builder =
new DefaultConfigurationBuilder(“config.xml”);
boolean load =true;
CombinedConfiguration config = builder.getConfiguration(load);
config.setExpressionEngine(new XPathExpressionEngine());
String env = config.getString(“ENV_TYPE”);
if(“dev”.equals(env) ||”production”.equals(env)) {
String xpath =”databases/database[name = ‘”+ env +”’]/url”;
return config.getString(xpath);
}else{
String msg =”ENV_TYPE environment variable is “+
“not properly set”;
throw new IllegalStateException(msg);
}
}
當基于文件的配置變化的時候自動加載,因為我們可以設置加載策略。框架會輪詢配置文件,當文件的內容發生改變時,配置對象也會刷新。你可以用程序控制:
XMLConfiguration config =new XMLConfiguration("springok1.xml");
ReloadingStrategy strategy =new FileChangedReloadingStrategy();
((FileChangedReloadingStrategy) strategy).setRefreshDelay(5000);
config.setReloadingStrategy(strategy);或者配置的時候控制:
<?xmlversion="1.0"encoding="UTF-8"?><!-- config.xml --><configuration>
<env/>
<xmlfileName="const.xml">
<reloadingStrategyrefreshDelay="5000" config-class="org.apache.commons.configuration.reloading.FileChangedReloadingStrategy"/>
</xml></configuration>下面是dom和sax方式的手動解析方式可參考使用。
java語言中xml解析有很多種方式,最流行的方式有sax和dom兩種。
1. dom是把所有的解析內容一次性加入內存所以xml內容大的話性能不好。
2. sax是驅動解析。所以內存不會占用太多。(spring用的就是sax解析方式)
需要什么包自己到網上找下吧?
xml文件如下:
<?xml version="1.0" encoding="GB2312"?> <RESULT> <VALUE> <NO>springok1</NO> <ADDR>springok</ADDR> </VALUE> <VALUE> <NO>springok2</NO> <ADDR>springok</ADDR> </VALUE> </RESULT>
DOM是用與平臺和語言無關的方式表示XML文檔的官方W3C標準。DOM是以層次結構組織的節點或信息片斷的集合。這個層次結構允許開發人員在樹中尋找特定信息。分析該結構通常需要加載整個文檔和構造層次結構,然后才能做任何工作。由于它是基于信息層次的,因而DOM被認為是基于樹或基于對象的。DOM以及廣義的基于樹的處理具有幾個優點。首先,由于樹在內存中是持久的,因此可以修改它以便應用程序能對數據和結構作出更改。它還可以在任何時候在樹中上下導航,而不是像SAX那樣是一次性的處理。DOM使用起來也要簡單得多。
import java.io.*; import java.util.*; import org.w3c.dom.*; import javax.xml.parsers.*; public class MyXMLReader{
public static void main(String arge[]){
long lasting =System.currentTimeMillis(); try{
File f=new File("data_10k.xml"); DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); DocumentBuilder builder=factory.newDocumentBuilder(); Document doc = builder.parse(f); NodeList nl = doc.getElementsByTagName("VALUE"); for (int i=0;i<nl.getLength();i++){ System.out.print("車牌號碼:" + doc.getElementsByTagName("NO").item(i).getFirstChild().getNodeValue()); System.out.println("車主地址:" + doc.getElementsByTagName("ADDR").item(i).getFirstChild().getNodeValue()); }
}catch(Exception e){
e.printStackTrace(); }SAX處理的優點非常類似于流媒體的優點。分析能夠立即開始,而不是等待所有的數據被處理。而且,由于應用程序只是在讀取數據時檢查數據,因此不需要將數據存儲在內存中。這對于大型文檔來說是個巨大的優點。事實上,應用程序甚至不必解析整個文檔;它可以在某個條件得到滿足時停止解析。一般來說,SAX還比它的替代者DOM快許多。 選擇DOM還是選擇SAX? 對于需要自己編寫代碼來處理XML文檔的開發人員來說, 選擇DOM還是SAX解析模型是一個非常重要的設計決策。 DOM采用建立樹形結構的方式訪問XML文檔,而SAX采用的事件模型。 DOM解析器把XML文檔轉化為一個包含其內容的樹,并可以對樹進行遍歷。用DOM解析模型的優點是編程容易,開發人員只需要調用建樹的指令,然后利用navigation APIs訪問所需的樹節點來完成任務。可以很容易的添加和修改樹中的元素。然而由于使用DOM解析器的時候需要處理整個XML文檔,所以對性能和內存的要求比較高,尤其是遇到很大的XML文件的時候。由于它的遍歷能力,DOM解析器常用于XML文檔需要頻繁的改變的服務中。 SAX解析器采用了基于事件的模型,它在解析XML文檔的時候可以觸發一系列的事件,當發現給定的tag的時候,它可以激活一個回調方法,告訴該方法制定的標簽已經找到。SAX對內存的要求通常會比較低,因為它讓開發人員自己來決定所要處理的tag.特別是當開發人員只需要處理文檔中所包含的部分數據時,SAX這種擴展能力得到了更好的體現。但用SAX解析器的時候編碼工作會比較困難,而且很難同時訪問同一個文檔中的多處不同數據。
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class MyXMLReader extends DefaultHandler { java.util.Stack tags = new java.util.Stack();
public MyXMLReader() {
super();
}
public static void main(String args[]) {
long lasting = System.currentTimeMillis();
try {
SAXParserFactory sf = SAXParserFactory.newInstance();
SAXParser sp = sf.newSAXParser();
MyXMLReader reader = new MyXMLReader();
sp.parse(new InputSource("data_10k.xml"), reader);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("運行時間:" + (System.currentTimeMillis() - lasting) + "毫秒");}
public void characters(char ch[], int start, int length) throws SAXException {
String tag = (String) tags.peek();
if (tag.equals("NO")) {
System.out.print("車牌號碼:" + new String(ch, start, length));
}
if (tag.equals("ADDR")) {
System.out.println("地址:" + new String(ch, start, length));
}
}
public void startElement(String uri,String localName,String qName,Attributes attrs) {
tags.push(qName);}
}**
總結:個人喜歡這個框架,支持定時刷新、xpath、import方式。
近期項目自己手寫一個字符串連接池。因為環境不同有開發版本、測試版本、上線版本、每一個版本用到的數據庫也是不一樣的。所以需要能靈活的切換數據庫連接。當然這個用maven就解決了。Apache Commons Configuration 框架用的主要是解析數據庫連接字符串。
下面介紹Apache Commons Configuration 框架的常用部分。
**
下載jar包http://www.php.cn/或者http://www.php.cn/ maven中搜索下載
研究api的使用。
·當xml結構大變化的時候不用過多的修改解析xml的代碼
用戶只需要修改自己的解析語法樹即可。
客戶只需要修改語法樹框架去解析,思考的起點是不是跟設計模式中的解釋器模式類似。構建抽象語法樹并解釋執行。
用戶只需要關心和修改自己的解析語法樹即可。
用戶不用關系如何解析只需要配置對應的解析語法規則即可。
簡化程序xml配置結構變化后大幅度的修改代碼。
首先先配置一下Maven。
<dependency>
<groupId>commons-configuration</groupId>
<artifactId>commons-configuration</artifactId>
<version>1.8</version>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>commons-jxpath</groupId>
<artifactId>commons-jxpath</artifactId>
<version>1.3</version>
</dependency>定義一個springok1.xml內容如下
<?xml version="1.0" encoding="UTF-8"?><!-- springok1.xml --><config>
<database>
<url>127.0.0.1</url>
<port>3306</port>
<login>admin</login>
<password></password>
</database></config>public static void main(String[] args) throws Exception {
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
System.out.println(conf.getString("database.url"));
System.out.println(conf.getString("database.port"));
System.out.println(conf.getString("database.login"));
System.out.println(conf.getString("database.password"));
}輸出如下:說明已經成功解析xml了。
127.0.0.1
3306
admin
獲取的方法有很多種更詳細的獲取方法可以從AbstractConfiguration方法中對應找到。
上面配置的是一個數據庫的連接信息,如果配置很多數據庫的連接信息,怎么解析連接信息切換呢。修改springok1.xml的信息為多個連接配置如下:
<?xml version="1.0" encoding="UTF-8"?><!-- springok1.xml --><config><databases>
<database>
<url>127.0.0.1</url>
<port>3306</port>
<login>admin</login>
<password></password>
</database>
<database>
<url>127.0.0.1</url>
<port>3302</port>
<login>admin</login>
<password>admin</password>
</database></databases></config>現在假設我們要獲取兩個的配置數據庫連接信息,程序如下:
public static void main(String[] args) throws Exception {
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
System.out.println(conf.getString("databases.database(0).url"));
System.out.println(conf.getString("databases.database(0).port"));
System.out.println(conf.getString("databases.database(0).login"));
System.out.println(conf.getString("databases.database(0).password"));
System.out.println(conf.getString("databases.database(1).url"));
System.out.println(conf.getString("databases.database(1).port"));
System.out.println(conf.getString("databases.database(1).login"));
System.out.println(conf.getString("databases.database(1).password"));
}輸出:
127.0.0.1
3306
admin
127.0.0.1
3302
admin
admin
解析ok,
結合前面的配置文件的例子跟實戰我們發現多個相同的標簽的話索引是從0開始的。
點的訪問方式上面的那種方式是沒問題,對于一些復雜的配置來講,我們可能需要使用XPath表達式語言。這里的主要優點是,使用了XML的高級查詢,程序看起來仍然比較簡潔易懂。可理解性高。
還是解析上面的springok.xml文件。代碼如下:
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
conf.setExpressionEngine(new XPathExpressionEngine());
System.out.println(conf.getString("databases/database[port='3306']/url"));
System.out.println(conf.getString("databases/database[port='3302']/port"));輸出:
127.0.0.1
3302
測試ok.
EnvironmentConfiguration conf=new EnvironmentConfiguration();
System.out.println(conf.getMap());源碼分析如何實現:
public EnvironmentConfiguration()
{ super(new HashMap<String, Object>(System.getenv()));
}聯合一和2兩種方式,是不是我們可以再系統變量中定義一個需要連接的數據庫字符串key,解析的時候獲取動態加載呢?
public String getDbUrl() throws ConfigurationException {
EnvironmentConfiguration envConfig =new EnvironmentConfiguration(); String env = envConfig.getString("ENV_TYPE"); if("dev".equals(env) ||"production".equals(env)) {
XMLConfiguration xmlConfig =new XMLConfiguration("springok1.xml");
xmlConfig.setExpressionEngine(new XPathExpressionEngine()); String xpath ="databases/database[name = '"+ env +"']/url"; return xmlConfig.getString(xpath);
}else{ String msg ="ENV_TYPE environment variable is "+
"not properly set";
throw new IllegalStateException(msg);
}
}測試ok沒問題。
xml配置如下圖:
public String getDbUrl()throws ConfigurationException {
DefaultConfigurationBuilder builder =
new DefaultConfigurationBuilder(“config.xml”);
boolean load =true;
CombinedConfiguration config = builder.getConfiguration(load);
config.setExpressionEngine(new XPathExpressionEngine());
String env = config.getString(“ENV_TYPE”);
if(“dev”.equals(env) ||”production”.equals(env)) {
String xpath =”databases/database[name = ‘”+ env +”’]/url”;
return config.getString(xpath);
}else{
String msg =”ENV_TYPE environment variable is “+
“not properly set”;
throw new IllegalStateException(msg);
}
}
當基于文件的配置變化的時候自動加載,因為我們可以設置加載策略。框架會輪詢配置文件,當文件的內容發生改變時,配置對象也會刷新。你可以用程序控制:
XMLConfiguration config =new XMLConfiguration("springok1.xml");
ReloadingStrategy strategy =new FileChangedReloadingStrategy();
((FileChangedReloadingStrategy) strategy).setRefreshDelay(5000);
config.setReloadingStrategy(strategy);或者配置的時候控制:
<?xmlversion="1.0"encoding="UTF-8"?><!-- config.xml --><configuration>
<env/>
<xmlfileName="const.xml">
<reloadingStrategyrefreshDelay="5000" config-class="org.apache.commons.configuration.reloading.FileChangedReloadingStrategy"/>
</xml></configuration>下面是dom和sax方式的手動解析方式可參考使用。
java語言中xml解析有很多種方式,最流行的方式有sax和dom兩種。
1. dom是把所有的解析內容一次性加入內存所以xml內容大的話性能不好。
2. sax是驅動解析。所以內存不會占用太多。(spring用的就是sax解析方式)
需要什么包自己到網上找下吧?
xml文件如下:
<?xml version="1.0" encoding="GB2312"?> <RESULT> <VALUE> <NO>springok1</NO> <ADDR>springok</ADDR> </VALUE> <VALUE> <NO>springok2</NO> <ADDR>springok</ADDR> </VALUE> </RESULT>
DOM是用與平臺和語言無關的方式表示XML文檔的官方W3C標準。DOM是以層次結構組織的節點或信息片斷的集合。這個層次結構允許開發人員在樹中尋找特定信息。分析該結構通常需要加載整個文檔和構造層次結構,然后才能做任何工作。由于它是基于信息層次的,因而DOM被認為是基于樹或基于對象的。DOM以及廣義的基于樹的處理具有幾個優點。首先,由于樹在內存中是持久的,因此可以修改它以便應用程序能對數據和結構作出更改。它還可以在任何時候在樹中上下導航,而不是像SAX那樣是一次性的處理。DOM使用起來也要簡單得多。
import java.io.*; import java.util.*; import org.w3c.dom.*; import javax.xml.parsers.*; public class MyXMLReader{
public static void main(String arge[]){
long lasting =System.currentTimeMillis(); try{
File f=new File("data_10k.xml"); DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); DocumentBuilder builder=factory.newDocumentBuilder(); Document doc = builder.parse(f); NodeList nl = doc.getElementsByTagName("VALUE"); for (int i=0;i<nl.getLength();i++){ System.out.print("車牌號碼:" + doc.getElementsByTagName("NO").item(i).getFirstChild().getNodeValue()); System.out.println("車主地址:" + doc.getElementsByTagName("ADDR").item(i).getFirstChild().getNodeValue()); }
}catch(Exception e){
e.printStackTrace(); }SAX處理的優點非常類似于流媒體的優點。分析能夠立即開始,而不是等待所有的數據被處理。而且,由于應用程序只是在讀取數據時檢查數據,因此不需要將數據存儲在內存中。這對于大型文檔來說是個巨大的優點。事實上,應用程序甚至不必解析整個文檔;它可以在某個條件得到滿足時停止解析。一般來說,SAX還比它的替代者DOM快許多。 選擇DOM還是選擇SAX? 對于需要自己編寫代碼來處理XML文檔的開發人員來說, 選擇DOM還是SAX解析模型是一個非常重要的設計決策。 DOM采用建立樹形結構的方式訪問XML文檔,而SAX采用的事件模型。 DOM解析器把XML文檔轉化為一個包含其內容的樹,并可以對樹進行遍歷。用DOM解析模型的優點是編程容易,開發人員只需要調用建樹的指令,然后利用navigation APIs訪問所需的樹節點來完成任務。可以很容易的添加和修改樹中的元素。然而由于使用DOM解析器的時候需要處理整個XML文檔,所以對性能和內存的要求比較高,尤其是遇到很大的XML文件的時候。由于它的遍歷能力,DOM解析器常用于XML文檔需要頻繁的改變的服務中。 SAX解析器采用了基于事件的模型,它在解析XML文檔的時候可以觸發一系列的事件,當發現給定的tag的時候,它可以激活一個回調方法,告訴該方法制定的標簽已經找到。SAX對內存的要求通常會比較低,因為它讓開發人員自己來決定所要處理的tag.特別是當開發人員只需要處理文檔中所包含的部分數據時,SAX這種擴展能力得到了更好的體現。但用SAX解析器的時候編碼工作會比較困難,而且很難同時訪問同一個文檔中的多處不同數據。
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class MyXMLReader extends DefaultHandler { java.util.Stack tags = new java.util.Stack();
public MyXMLReader() {
super();
}
public static void main(String args[]) {
long lasting = System.currentTimeMillis();
try {
SAXParserFactory sf = SAXParserFactory.newInstance();
SAXParser sp = sf.newSAXParser();
MyXMLReader reader = new MyXMLReader();
sp.parse(new InputSource("data_10k.xml"), reader);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("運行時間:" + (System.currentTimeMillis() - lasting) + "毫秒");}
public void characters(char ch[], int start, int length) throws SAXException {
String tag = (String) tags.peek();
if (tag.equals("NO")) {
System.out.print("車牌號碼:" + new String(ch, start, length));
}
if (tag.equals("ADDR")) {
System.out.println("地址:" + new String(ch, start, length));
}
}
public void startElement(String uri,String localName,String qName,Attributes attrs) {
tags.push(qName);}
}關于Apache Commons Configuration讀取xml配置的方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





