溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
〇、經驗總結:
一、背景說明
這周我們對項目里新增的幾個接口進行了壓力測試,期間遇到了一些之前沒有遇到過的坑,走了一些彎路,在這里對這次壓力測試經歷進行總結復盤,同時也希望能給看到這篇文章的諸位提供一些淺顯的思路。
首先介紹一下我們項目的結構。服務入口是一個網關模塊,提供一個Grpc類型的接口,數據傳輸模式是一元數據模式。網關模塊與其他業務模塊之間通過Dubbo接口進行交互。
服務的架構概況圖如下:
該業務接口部署的服務器配置和部署MySQL組件的服務器配置一致,都是4核8G,50G普通硬盤,并且處于同一個內網網段,我們預估的性能指標要達到300并發,600TPS。
在壓力測試過程中,我們重點關注TPS、GC次數、CPU占用率和接口響應時間等指標。
二、測試過程
完成項目部署后,我們開始編輯jemeter測試腳本,設置壓力測試的標準為300個并發線程,在10秒內全部啟動,持續壓測時間15分鐘,接著開始啟動jemeter腳本進行測試。
1、第一次壓力測試
垃圾收集策略包括:老年代啟用CMS垃圾收集算法,新生代啟用ParNew垃圾收集算法,新生代最大存活周期為15次minorGC,FullGC時使用CMS算法,并開啟CMS中的并行標記。
根據前幾次的壓力測試經驗,我們將初始堆內存設置為2048MB,因為偏小的堆內存設置容易在壓力測試時被撐爆。
JVM內存分配:最大/最小堆內存為2048MB,Eden和Survivor比例為8:2,新生代和老年代的比例為1:2。由于服務器安裝的是JDK8版本,廢棄了永久代的配置。
JVM配置參數如下:
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-Xloggc:/var/log/$MODULE/gc.log
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:MaxTenuringThreshold=15
-XX:+ExplicitGCInvokesConcurrent
-XX:+CMSParallelRemarkEnabled
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/log/$MODULE
-Xmx2048m -Xms2048m
-XX:SurvivorRatio=8(2)性能指標監控
top命令觀察java線程的CPU占用率(us表示用戶進程,sy表示系統進程),并使用jstac -gcutil Pid 1000 命令,定期查看虛擬機的GC情況。
一切準備就緒后,我們開始跑壓測腳本,并查看性能監控指標。
但是我們沒有看到預期來臨的壓力,而是并發到達一定值時,好像突然并發壓力中斷了,然后間隔1-2秒后壓力又重新出現,這期間接口服務器各項指標均沒有異常。很顯然,并發存在問題!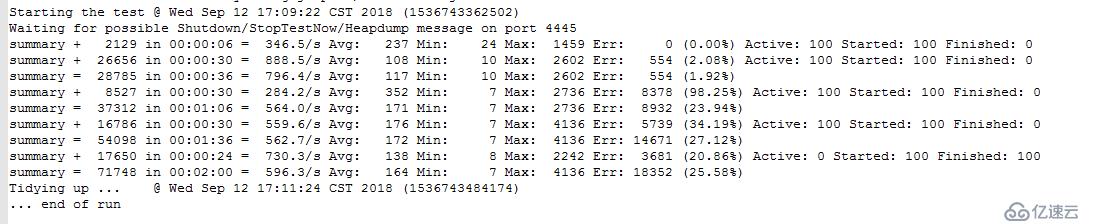
(3)問題排查與解決
上述壓測過程中出現的現象,可以細分為兩類:
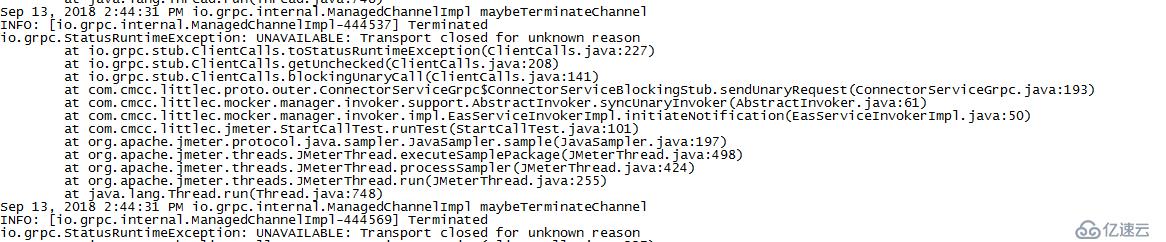
由于Grpc接口需要在客戶端與服務端建立RPC連接,那么兩端都需要同時指定各自的一個端口進行數據通信。基于這一點,我們判斷出現第一種現象的原因可能有兩個:
cat /proc/sys/net/ipv4/ip_local_port_range結果是: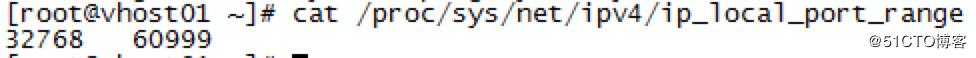
即僅放開了 32768——60999 之間的端口,數量大致也是3W左右。
然后我們重新設置了被壓機器的端口擴展列表,命令:
echo "10000 65535" > /proc/sys/net/ipv4/ip_local_port_range結果是:
2、第二次壓力測試
經過第一次壓力測試調整后,我們開始對調整效果進行測試驗證。
(1)JVM配置
JVM配置沒有改變
(2)性能指標監控
查看被壓機器的GC情況和CPU使用情況,依然沒有太大變化,但請求數量稍微有所提升,說明端口擴展有一定的效果,但是不明顯。
繼續查看施壓機器的信息,接口調用的結果斷言依然存在錯誤,雖然錯誤率有所降低(跟被壓機器接收請求的數量上升有關系),錯誤信息還是連接異常。

從這個結果來看,解決問題的方向是對的,于是繼續把施壓機器的端口擴展放開,開始第三輪測試驗證。
3、第三次壓力測試
(1)JVM配置
JVM配置沒有改變
(2)性能指標監控
施壓機器和被壓機器的端口列表都放開后,grpc連接請求都正常了。在100并發和300并發兩種情況下,持續2分鐘發起的請求數相差不大,說明已經接近了兩端服務器的處理極限了。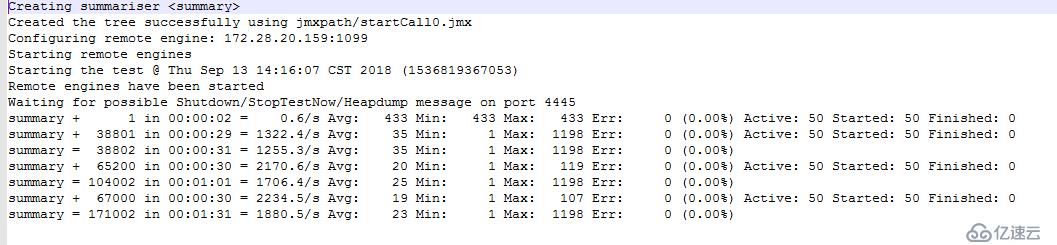
(3)新問題暴露
本來以為這樣就OK了,然而此時突然發現被壓機器的GC開始出現異常,即YGC次數開始不變動,但是FGC頻繁。
壓測一段時間后,FGC開始出現,頻率為平均每秒2-3次。
通常出現FGC的原因,無非就是老年代被占滿了,于是查看線程的老年代堆內存情況:
jstat -gcold PID
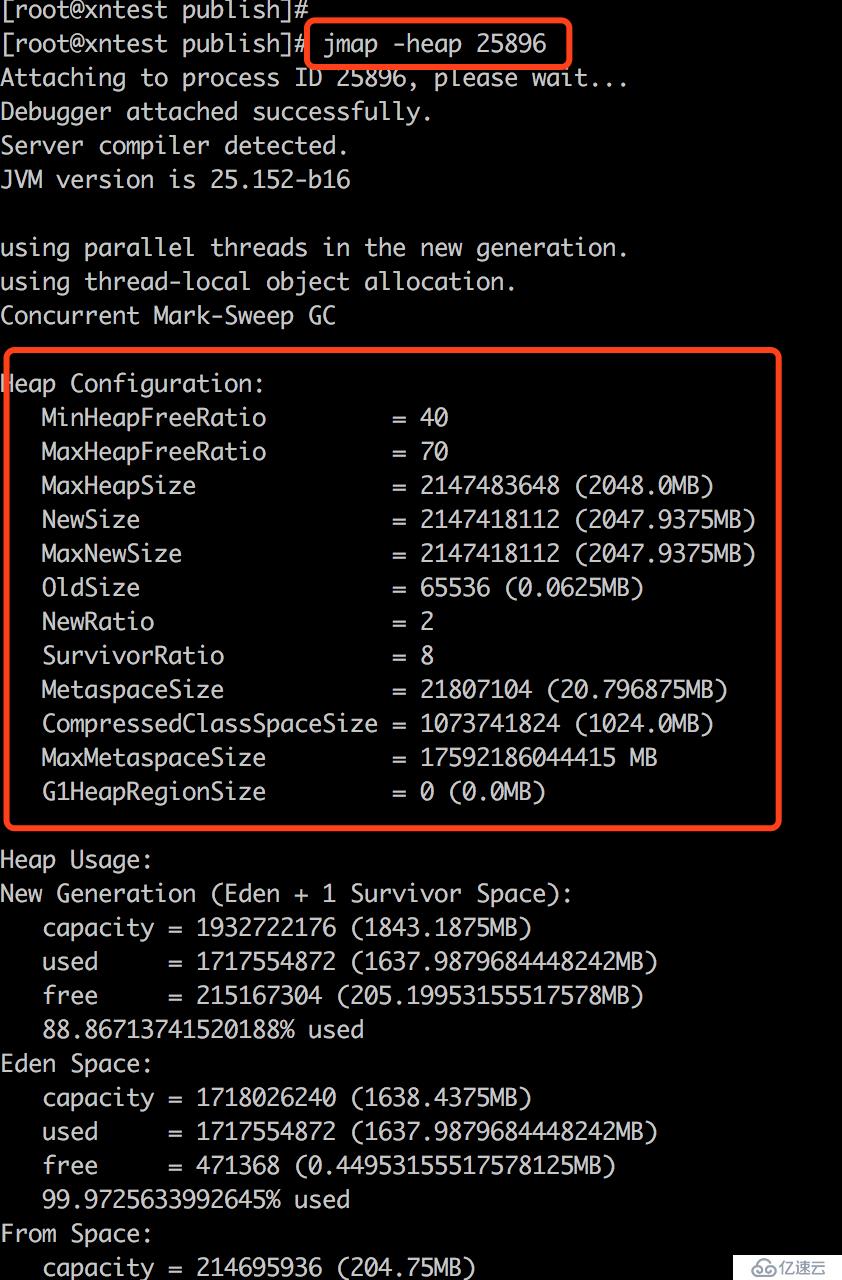
我的天!老年代才64KB!這是把新生代內存塞滿后,開始往可憐巴巴的老年代塞了,于是頻繁觸發FGC。
于是查看JVM參數配置,發現少了老年代的內存配置了。
老年代的堆內存配置可以通過 -XX:NewRatio=3 來設置,表示老生代:新生代的比值。即如果2GB堆內存的話,那么老年代是1.5GB,新生代是0.5GB。
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/var/log/$MODULE/gc.log -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:MaxTenuringThreshold=15 -XX:+ExplicitGCInvokesConcurrent -XX:+CMSParallelRemarkEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/$MODULE -Xmx2048m -Xms2048m -XX:SurvivorRatio=8 -XX:NewRatio=3
配置好之后,重啟被壓測模塊,查看進程的堆內存分配情況: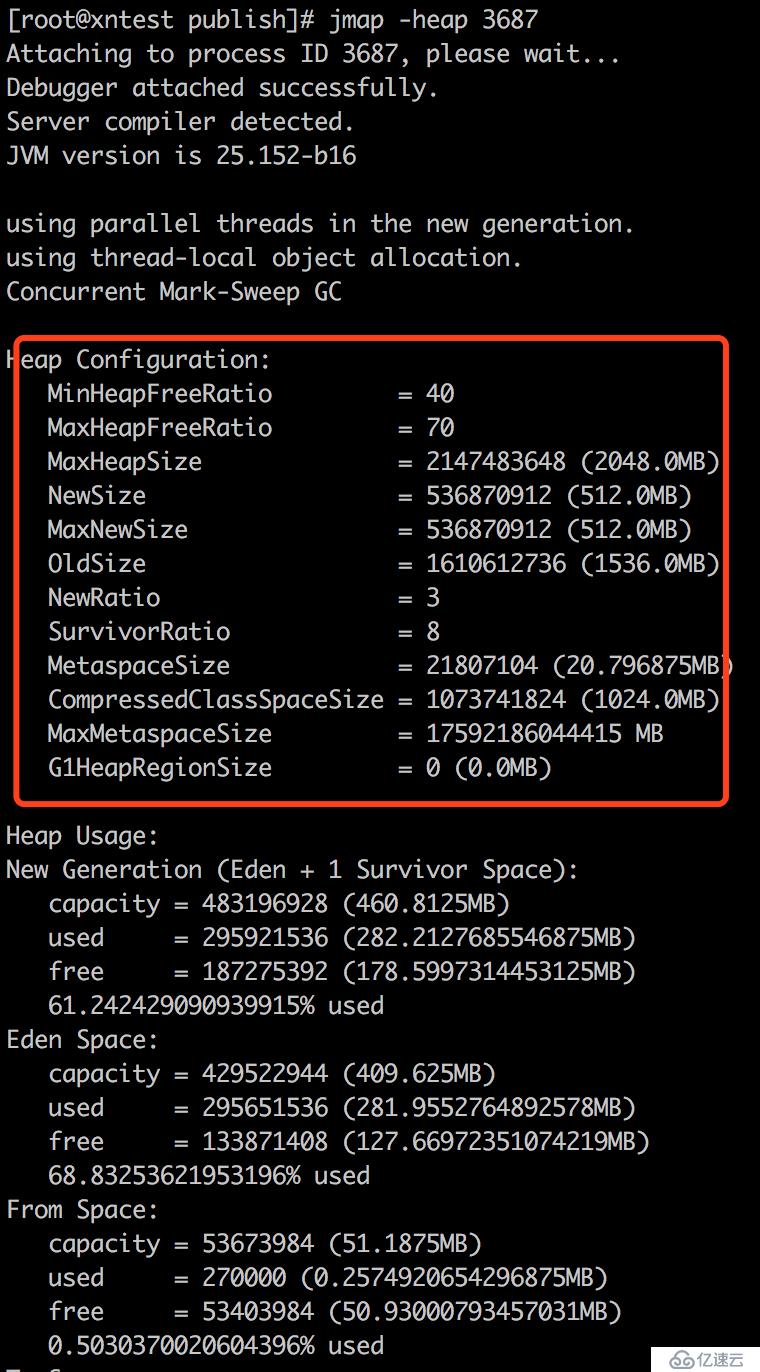
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





